멀티모달과 멀티에이전트 조합
Agent의 변화와 정의
ReAct: Synergizing Reasoning and Acting in Language Models, 2023.
Counterfactual Multi-Agent Policy Gradients, 2024.
Agent는 전통적인 관점에서 policy를 가지며, 자율적으로 판단하고 행동하는 모델을 말한다. 오래 전부터 강화학습 분야에서 사용되던 용어다. Policy를 가진 네트워크는 학습을 거쳐야 하며, 학습된 경험을 바탕으로 판단을 내린다. 최근에는 LLM의 체급을 믿고 LLM 자체를 두뇌로 사용하는 agent가 등장하기 시작했다. 대표적으로 ReAct(Reasoning and Acting) 프레임워크가 있다. 이러한 형태의 agent는 LLM이 가진 배경지식이 있기 때문에 별도의 학습을 하지 않거나, 경험을 외부에 저장한 뒤 입력 프롬프트로 넣어주는 context learning을 사용한다.
본 글에서 소개하는 agent 학습은 전자(강화학습)에 대한 이야기이다. 비록 LLM이 높은 범용성과 방대한 지식을 가지고 있지만, 더 전문적이고 세부적인 특징을 찾아내기 위해서는 직접 policy를 학습할 필요가 있다. 게다가 LLM을 fine-tune하는 접근법은 학습과 추론 시에 엄청난 컴퓨팅 파워가 필요하다는 한계도 있다. 이러한 문제 때문에 여전히 전통적인 강화학습 기반 agent가 사용되고 있다.
Agent가 좋은 성능을 보이다보니 자연스럽게 여러 agent를 이용해 성능을 높이는 연구가 등장했다. 대표적인 구조로 Actor-Critic이 있다. Actor는 직접 행동하며 경험을 학습하고, Critic은 actor의 판단을 평가하고 피드백을 제공한다. 이렇게 여러 agent를 동시에 운용하기 위해 효율적인 협업에 대해 논의하기 시작했다. 예를 들어, 분산된(decentralized) 환경에서 각 에이전트가 경험을 쌓고, 하나의 중앙화된(centralized) 학습을 거쳐 가중치를 업데이트하는 구조가 좋은 성능을 보이고 있다.
또 하나의 주목할만한 부분은 강화학습과 지도학습의 경계가 모호해지고 있다는 점이다. 정답 레이블을 맞추는 문제와 policy를 학습하는 문제를 모두 Loss function에 포함시켜 동시에 두 가지 문제를 학습하는 연구를 종종 확인할 수 있다.
Multi-modal과 multi-agent
Cooperative Sentiment Agents for Multimodal Sentiment Analysis, 2024.
Multi-modal은 여러 모달리티를 각 encoder가 분석한 뒤 fusion을 통해 하나의 출력을 만드는 구조를 가진다. 이는 각 agent가 경험을 통해 판단을 한 뒤 협업을 통해 공통된 과제를 수행하는 모습과 닮아있다. 본 글에서는 ‘감정 분석’ 문제를 예시로, multi-modal & multi-agent 문제를 어떻게 푸는지 소개한다.
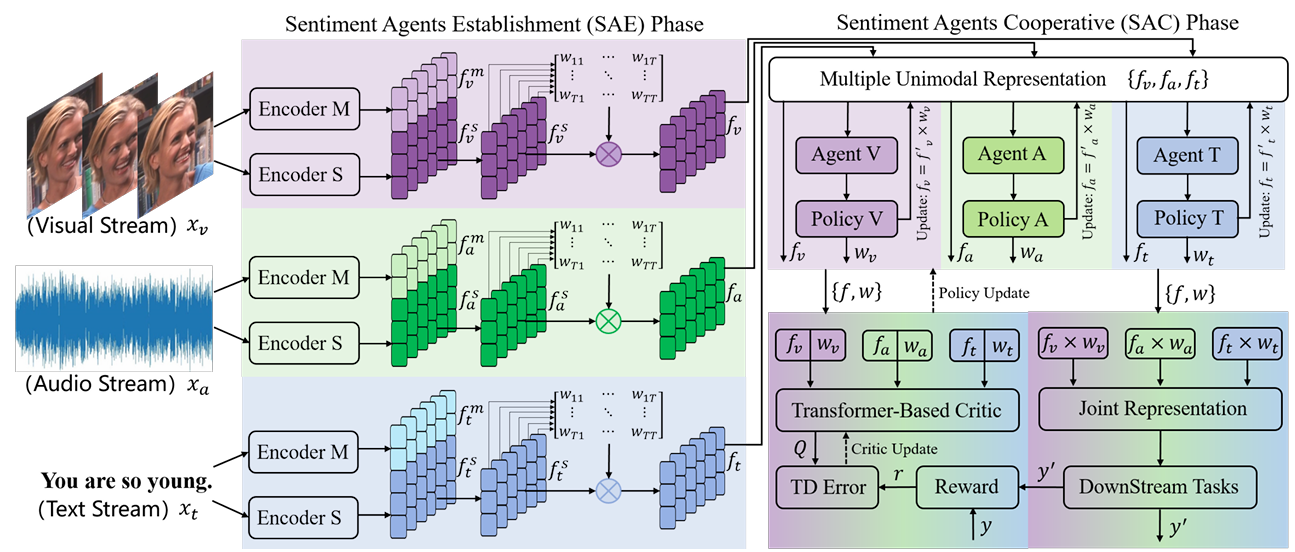
아이디어는 간단하다. 영상에서 감정을 분석하기 위해 각 모달리티에 대한 특징과 감정 정보를 인코딩한 뒤, policy를 통해 각 모달리티에 대한 정보를 얼마나 반영할지 판단하고 최종 출력을 만드는 구조다. 더 자세히 보면, SAE 단계에서 각 agent는 2개의 인코더를 통해 모달리티의 특징과 감정 정보를 추출한다. SAC 단계에서는 추출된 특징을 하나의 공통된 표현으로 변환해 어떤 정보가 상대적으로 더 중요한지 판단한다. 마지막으로 downstream task를 풀고 최종 출력을 생성한다.
아이디어는 간단하지만 학습은 간단하지 않다. Encoder를 어떻게 학습할지, modality 간의 관계를 어떻게 학습할지, policy를 어떻게 학습할지 등 고려해야할 요소가 많다.
\[L=\alpha_1 L_p + \alpha_2 L_{msd} + \alpha_3 L_{dpsr} + \alpha_4 (L_{actor} + L_{critic})\]$\alpha_i$는 각 loss term에 대한 가중치이며,
- $L_p$: 감정 레이블에 대한 supervised learning
- $L_{msd}$:
- Modality 분류 학습 (각 벡터가 어떤 모달리티에서 왔는지)
- Modality와 Sentiment 간의 heterogeneity 학습
- 원본 입력 복원을 supervised로 학습
- $L_{dpsr}$: 시간에 따른 감정의 변화를 학습
- $L_{actor}$: 각 agent의 policy 학습
- $L_{critic}$: Agent의 평가자 학습
아래에서는 각 Loss term이 어떤 문제를 풀기 위해 사용되었으며 구체적인 식을 정의한다.
\(L_p\)는 감정 레이블에 대한 predictive loss를 사용한다. (구체적으로 논문에서는 2가지 감정 분류를 풀기 때문에 각 문제에 맞춰 Mean Absolute Loss와 Cross-Entropy Loss를 사용한다.)
\[L_m = -\cfrac{1}{3}\sum_{i}^{v,a,t}y_i\log F^m(f_i^m ; \theta^m)\]$L_m$은 feature vector인 $f^m$가 어떤 모달리티에서 왔는지를 평가한다. $y_v, y_a, y_t$는 각각 이미지, 오디오, 텍스트 레이블이며 순서대로 0, 1, 2로 두고 학습했다.
\[L_c = -\cfrac{1}{3}\sum_i^{v,a,t}d(f^s_i, f^m_i)\]$L_c$는 감정 feature $f^s$와 각 모달리티 feature $f^m$의 거리 $d$를 크게 만드는 문제로, 하나의 agent 내에서 감정을 담당하는 인코더와 모달리티를 담당하는 인코더가 겹치지 않는 정보를 학습하도록 유도한다.
\[L_r = \cfrac{1}{3}\sum_i^{v,a,t}d(x_i,\tilde{x}_i)\] \[\tilde{x}_i = D_i(f_i^s \oplus f_i^m ; \theta^d_i)\]$L_r$은 추출된 감정과 모달리티 특징을 이용해 원본 입력을 복원하는 문제를 학습한다. 이를 통해 특징 벡터에 입력 데이터의 정보가 얼마나 잘 보존되었는가를 알 수 있다.
\[L_{dpsr} = \frac{1}{T(T-1)} \sum_{p}^{T} \sum_{q \neq p}^{T} \eta_{pq} \left( \frac{(f_i)_p (f_i)_q}{\|(f_i)_p\| \|(f_i)_q\|} + 1 / 2 \right)\] \[f_i=W_if_i^s\] \[\eta_{pq} = T - \|p-q\|\]$L_{dpsr}$은 프레임 간 감정 벡터의 코사인 유사도를 최소화하도록 학습한다. 이를 통해 프레임 간 다른 감정 특징을 학습하도록 강제하기 때문에, 시간에 따라 변하는 감정 특징을 추출하도록 돕는다. 추가로 $\eta_{pq}$를 가중치로 반영해 가까운 프레임 간의 차이를 더 많이 반영하도록 조절한다.
\[Q = F_c(\sum_i^{v,a,t}f_i\oplus w_i ; \theta_c)\]$L_{actor}$는 Q-value를 최대화하는 문제를 푼다.
\[L_{critic}=Q-\bar{Q}\] \[\bar{Q}=r+\gamma Q'\]\(Q'\)는 누적 보상이며, \(L_{critic}\)은 Temporal-Difference Error 알고리즘을 사용한다.
실험
\[f=(f_v\times w_v)*(f_a\times w_a)*(f_t\times w_t)\]최종적으로 feature $f$를 이용해 downstream task를 푼다. Visual encoder는 Facet, Acoustic encoder는 COVAREP, text encoder는 BERT를 사용했다.
결과
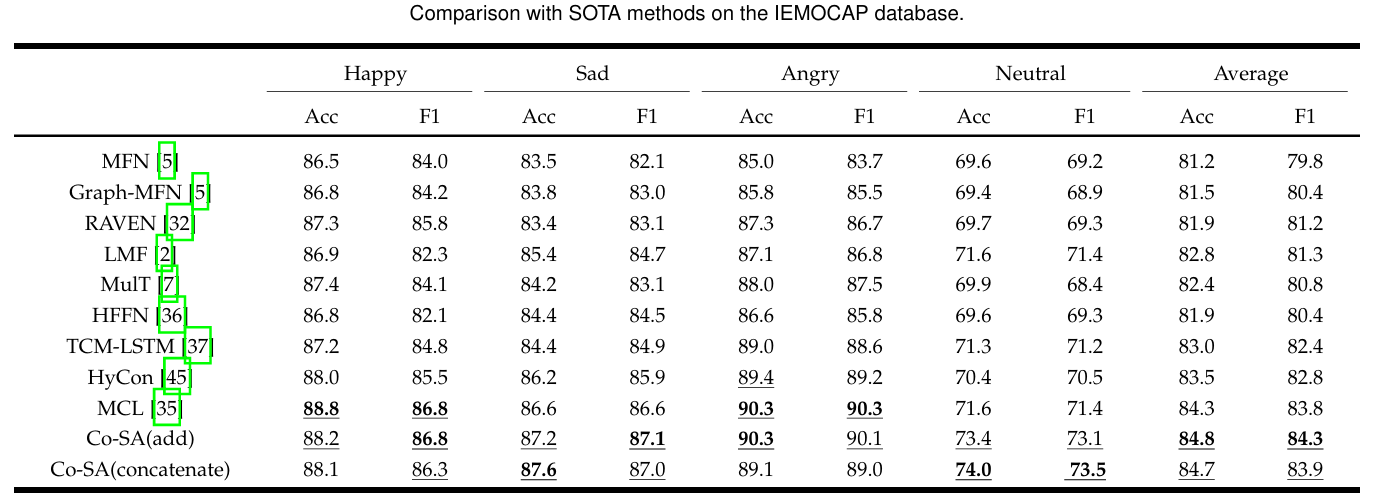
학습한 데이터 중 IEMCOCAP를 평가한 표이다. 본 논문에서 제안한 Co-SA가 모든 항목에서 좋은 성능을 보였다.
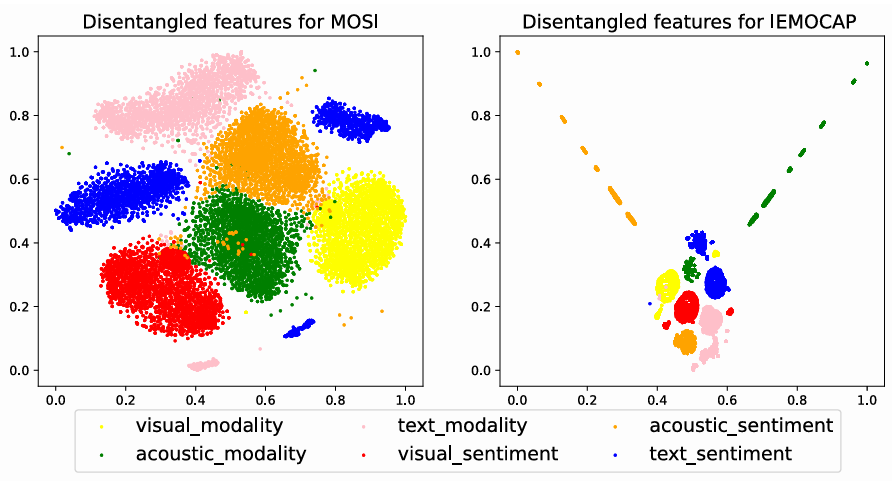
Feature가 학습된 공간을 보면 각 모달리티 별로 잘 분리되어 학습된 것을 확인할 수 있다. 같은 모달리티 내에서도 모달리티 특징과 감정 특징을 따로 학습해냈다.
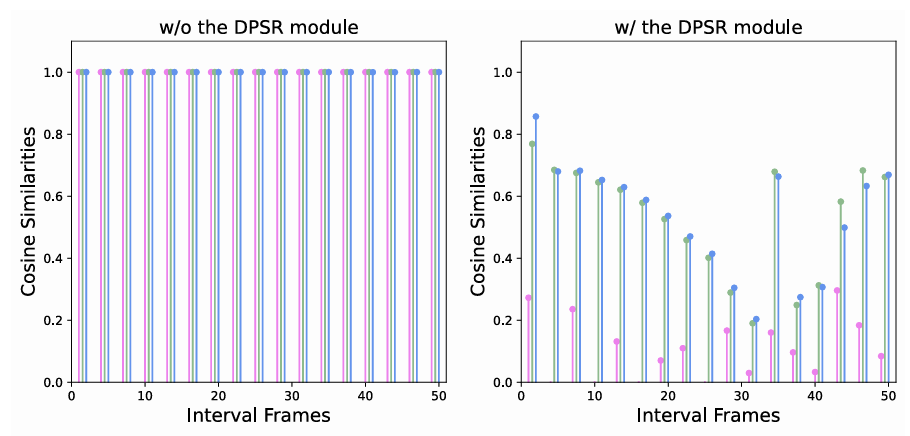
$L_{dpsr}$은 프레임 간 다른 감정 정보를 학습하도로 해 시간에 따른 감정 변화를 파악한다. 그래프는 프레임 간의 유사도가 작게 학습된 것을 볼 수 있다. 이를 통해 프레임의 특징적인 정보를 추출해 냈다고 해석할 수 있다.
본 글에서 소개한 논문은 멀티모달 문제를 멀티 에이전트 형식으로 풀어냈다. 무엇보다 Loss function을 매우 정교하게 설계함으로써 각 모달리티 별로, 에이전트 별로, 프레임 별로 다른 특징을 학습하도록 했다는 점이 흥미롭다.