Less is more, Reasoning Model의 등장
LLM을 활용한 연구가 쏟아지는 동시에 LLM의 한계도 점점 명확해져 가고 있다. 그로 인해 Microsoft의 BitNet과 같이 작은 모델을 만들기 위한 시도가 계속 이어져왔다. 그러다 최근 몇 달 동안 reasoning 분야에서 새로운 아키텍쳐가 논의되고 있다. 오늘은 Hierarchical Reasoning Model이라고 불리는 아키텍쳐에 대해 이야기해 보려 한다.
인간의 뇌에서 영감을 받다
Hierarchical Reasoning Model, 2025.
추론 문제를 풀기 위해 CoT(Chain-of-Thought) 같은 방법론이 제시되어 왔지만 기대만큼의 성능 향상을 보이지는 못했다. HRM(Hierarchical Reasoning Model)은 “latent reasoning”을 제안한다. 내부의 hidden state space에서 재귀적인 구조를 통해 여러 번 생각을 거쳐 답을 출력하는 구조를 말한다.
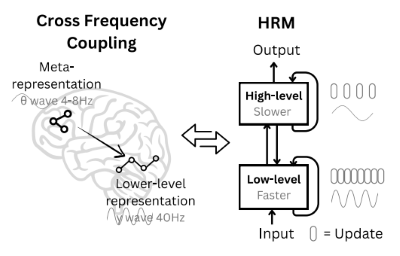
이러한 구조는 인간의 뇌가 추론하는 과정에서 영감을 받았다. 추론 과정을 high-level과 low-level로 나눌 수 있는데, high-level은 추상적인 개념을 이해하기 위해 천천히 생각한다면 low-level은 세부적인 계산을 빠르게 수행한다. 여러 번의 low-level 추론을 반복한 뒤 high-level 추론을 거치면 효율적으로 representation을 만들어낸다.
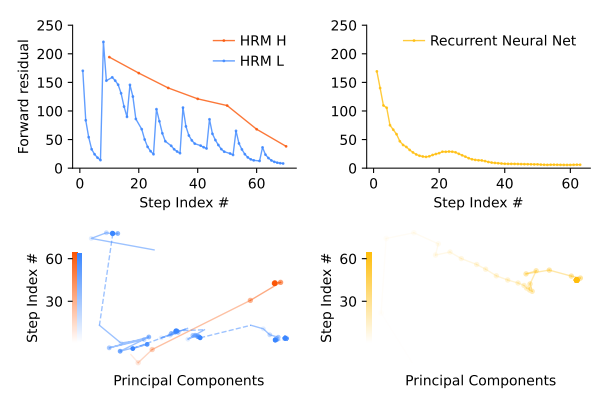
HRM의 forward residual을 보면 high-level(HRM H)는 일정하게 수렴한다. 그러면서 low-level(HRM L)은 일정 주기를 가지고 수렴한다. 이는 high-level에서 큰 방향을 결정하고, low-level은 high-level의 결정에 따라 반복 추론을 하는 모습을 볼 수 있다. HRM의 재귀 구조가 RNN과 유사해 보일 수 있는데, RNN은 모든 연산을 저장했다가 한 번에 업데이트 하는 BackPropagation Through Time을 사용하지만, HRM은 one-step approximation이라는 방법을 사용한다. 덕분에 RNN은 빠르게 수렴하는데 반해, HRM은 더 오랫동안 탐색하는 모습을 볼 수 있다.
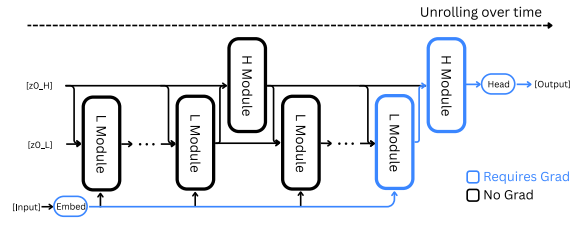
그림에서 볼 수 있듯이 HRM은 여러 번의 low-level 추론과 한 번의 high-level 추론이 결합된 구조이다. 이때 마지막에 발생한 한 번의 low-level과 high-level 추론의 gradient만 사용해 가중치를 업데이트한다. 이 방식은 latent vector가 하나의 고정된 점으로 수렴한다고 가정하기 때문에 가능한다. (물론 이 가정이 완벽하지 않아 뒤에서 소개할 TRM에서 이 논리를 반박한다.)
low-level의 반복 횟수는 모델이 직접 결정한다. 모델이 low-level을 반복할지, high-level로 넘어갈지 판단하는 과정을 ACT(Adaptive Computational Time)라고 한다. 판단 여부는 Q-learning으로 학습한다. 따라서 전체 Loss function은 네트워크를 자체를 학습하는 loss와 Q-learning을 위한 loss가 결합된 형태로 정의된다.
\[L^m_{ACT}=Loss(\hat{y}^m , y) + \text{BCE}(\hat{Q}^m, \hat{G}^m)\]모델의 입출력은 모두 토큰 시퀀스로 표현되며, low-level과 high-level 모듈 모두 동일한 차원의 encoder-only Transformer block으로 구현되었다.
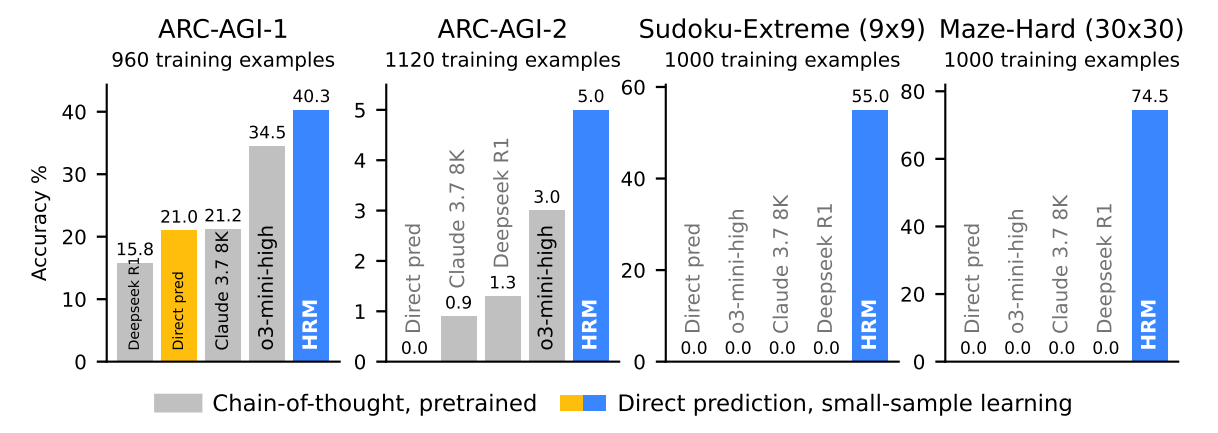
HRM이 스도쿠, 미로 등 고난이도 추론이 필요한 문제를 학습한 결과 o3-mini-high, Claude-3.7, Deepseek-R1보다 뛰어난 성능을 보였다. 이는 단순히 성능이 높아진 것을 넘어 훨씬 적은 파라미터(27M)로 학습해냈다는 데 큰 의미가 있다.
더 단순하게 만들 수 없을까
Less is More: Recursive Reasoning with Tiny Networks, 2025.
물론 HRM이 새로운 reasoning 구조를 제안했다는 데 큰 의의가 있지만, 여전히 의문이 드는 지점이 있다.
- 1-step gradient approximation은 타당한가?
- ACT가 반드시 필요한가?
- 구조를 더 단순하게 만들 수는 없는가?
삼성에서 제안한 TRM(Iiny Recursion Model)은 뇌과학에 기반한 접근 대신 공학적인 시각에서 모델을 바라본다. 그 덕분에 위에서 들었던 의문을 해결하고 더 단순하고 직관적인 구조를 제안한다.
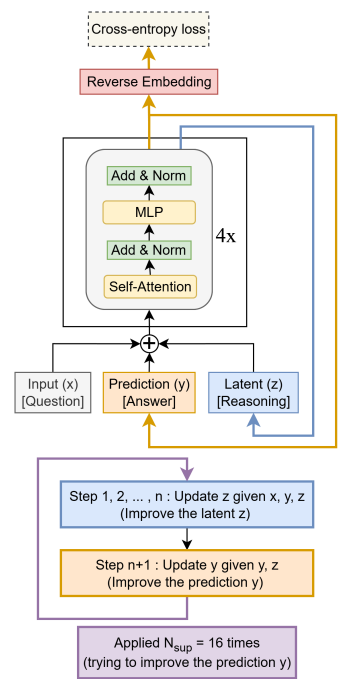
먼저, HRM은 1-step gradient approximation을 사용하지 않는다. HRM은 latent vector를 재귀 반복하며 추론하기 때문에 복잡한 수학적인 설명(IFT)이 필요했다. TRM은 low-level과 high-level을 구분하지 않고 하나의 네트워크가 완전한 출력을 생성한다. 이 출력을 다시 네트워크 입력으로 사용하며 재귀적인 forward pass를 수행한다. 그리고 마지막 한 번의 재귀 반복에 대해서만 gradient를 계산하고 back-propagate한다. 코드로 표현하면 다음과 같다.

따라서 HRM이 latent space를 계층으로 나눠 복잡하게 표현했던 것과 달리, TRM은 입출력을 더 단순하게 정의할 수 있다. 이제 입력하는 문제 $x$, 이전 출력 답변 $y$, latent reasoning feature $z$로 표현한다. 여기서 독립적인 단계별 $z$를 두거나, $z$와 $y$를 통합하는 방식도 시도했지만 성능이 하락했다.
이 외에도 저자는 많은 부분을 단순화했다. 네트워크의 경우, layer를 2개만 쌓았을 때 가장 좋은 성능을 보였다. 성능을 높이기 위해 layer를 4개까지 쌓아봤지만 오히려 성능이 떨어졌다고 한다. (참고로, 여기서 하나의 layer는 Self-Attention + MLP 구조의 Transformer block을 말한다.) Q-learning을 이용한 halt 학습도 없앴다. Binary-Cross Entropy를 통해 halt 여부를 함께 학습하도록 했으며, 성능에는 차이가 없었다.
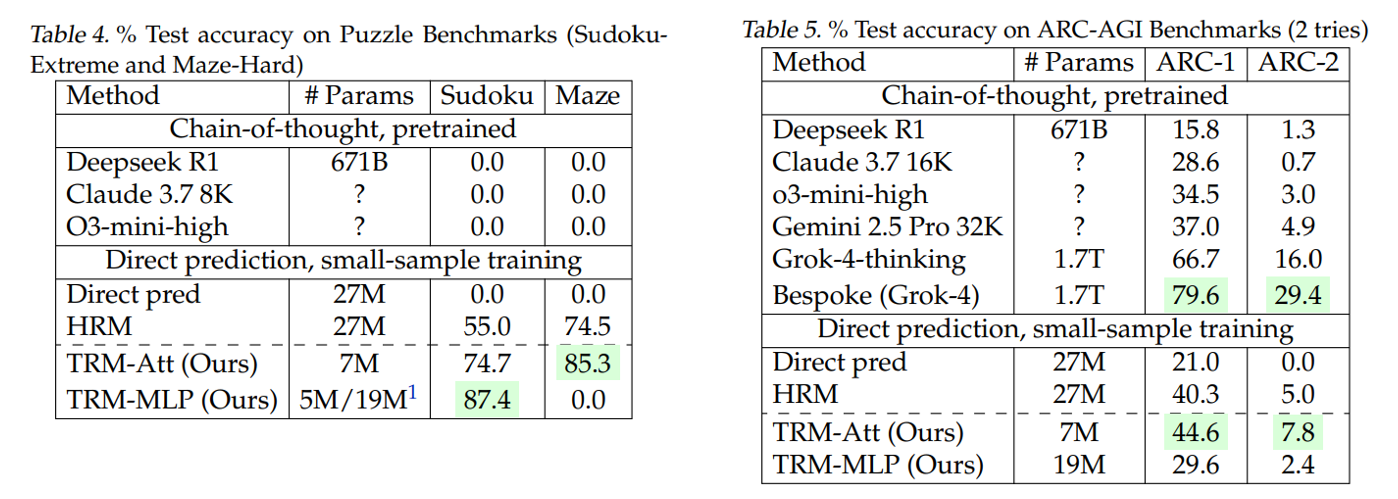
TRM은 훨씬 적은 파라미터(7M)로 LLM과 HRM의 성능을 뛰어넘었다. TRM-Att는 attention을 사용한 경우이고, TRM-MLP는 attention 대신 MLP만 사용한 경우다. Context 길이가 작은 문제에서는 TRM-MLP가 더 뛰어난 결과를 보이기도 했지만, context 크기가 커지면 attention을 사용한 모델이 더 좋은 일반화 성능을 보이는 것으로 드러났다. (아마도 inductive bias 때문으로 추정된다.)
참고문헌
- Hierarchical Reasoning Model, 2025.
- Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning, 2025.
- Less is More: Recursive Reasoning with Tiny Networks, 2025.
- 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs, 2024.