EEG 신호를 활용한 청소년 ADHD 진단
요약
Github: ADHD-EEG-ViT
주의력결핍 과잉행동장애(Attention deficit / hyperactivity disorder, ADHD)는 아동 및 청소년기에 가장 흔한 신경발달장애로, 조기에 적절한 진단과 개입이 이루어지지 않으면 학업 성취, 사회적 관계, 정서 발달에 장기적인 부정적 영향을 미칠 수 있다. ADHD 진단에 도움을 줄 수 있는 여러 뇌파 신호 중, EEG(Electroencephalogram)는 비침습적 방법으로 뇌 활동을 측정할 수 있어 신경과학 연구와 임상 진단 분야에서 널리 활용되고 있다.
본 연구는 EEG 신호를 활용해 청소년 ADHD 진단을 돕는 딥러닝 모델을 설계하고 실험했다. Vision-Transformer(A. Dosovitskiy et al., 2021)와 EEG-Transformer(Y. He et al., 2023)의 아이디어를 바탕으로 transformer 기반 모델을 구현했다. IEEE에서 제공하는 “EEG Data ADHD-Control Children” 데이터셋을 활용하여 0.972의 높은 정확도를 달성했다.
본 모델의 주요 장점은 다음과 같다.
- 별도의 복잡한 전처리 과정 없이 end-to-end 학습이 가능하다.
- Mixed precision 기법을 활용해 학습 속도를 높임과 동시에 높은 정확도를 기록했다.
- Embedding layer를 조정하여 다른 EEG 데이터셋에도 쉽게 적용할 수 있는 확장성을 고려했다.
다만, 학습 과정에서 모델의 과적합(overfitting) 현상을 발견했다. 이는 제한된 데이터셋으로 인한 것으로 보이며, 향후 추가 데이터 확보나 데이터 증강(data augmentation) 기법을 통해 모델의 안정성(robustness)을 개선할 수 있을 것으로 기대된다.
선행 연구 요약
EEG-Transformer(Y. He et al., 2023)는 Transformer(A. Vaswani et al., 2017)의 Self-Attention 구조를 그대로 차용한 EEG 분석 모델을 제안했다. 특히 Attention blocks, Residual connection, Normalization이 데이터 분석에 핵심적인 역할을 한다는 점을 강조했다.
또 다른 접근 방식으로 CNN을 활용한 연구들이 활발히 진행되었다. 그 중 비교적 최근 연구(M. Y. Esas and F. Latifoğlu)는 Robust Local Mode Decomposition (RLMD), Variational Model Decomposition (VMD)와 같은 전처리 기법을 사용해 데이터의 특징을 추출하고, 이를 CNN에 통과시켜 ADHD 여부를 판단한다.
데이터셋
본 연구에서는 IEEE data-port의 “EEG Data ADHD-Control Children” 데이터셋을 활용했다.
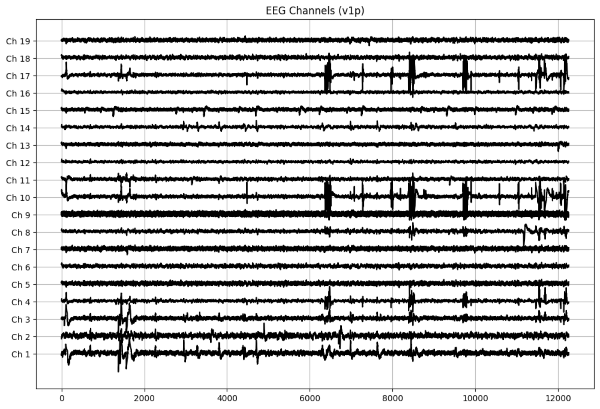
데이터 주요 특징은 다음과 같다.
- 총 121명의 참가자로, ADHD 그룹 61명과 건강한 대조군 60명으로 구성되어 있다.
- 7-12세 어린이를 대상으로 진행된 연구로, 전문가가 DSM-IV 기준에 따라 ADHD를 진단했다.
- EEG 신호는 10-20 standard*에 따라 19개 채널(Fz, Cz, Pz, C3, T3, C4, T4, Fp1, Fp2, F3, F4, F7, F8, P3, P4, T5, T6, O1, O2)로 기록되었으며, 128 Hz의 sampling frequency를 사용했다.
- 실험 방법은 아이들에게 캐릭터 사진을 보여주고 캐릭터의 수를 세도록 하는 과제를 제시했다.
데이터에 대한 정보가 명확하고, 두 그룹 간 균형이 잘 맞춰져 있어 연구에 적합한 데이터셋이다.
10-20 standard는 EEG 두피 전극 부착 위치에 대한 국제 표준이다. 데이터셋의 구체적인 전극 위치는 preprocess.ipynb에서 확인할 수 있다.
전처리
IEEE 데이터셋은 아이들이 캐릭터 수를 세는 과제 중 측정된 EEG 신호를 포함하고 있다. 참가자마다 과제 완료 시간이 다르기 때문에, EEG 신호의 길이도 다양하다. 구체적으로 신호 길이는 7,983부터 43,252까지 다양하며, 대체로 ADHD 그룹의 과제 완료 시간이 더 길었다.
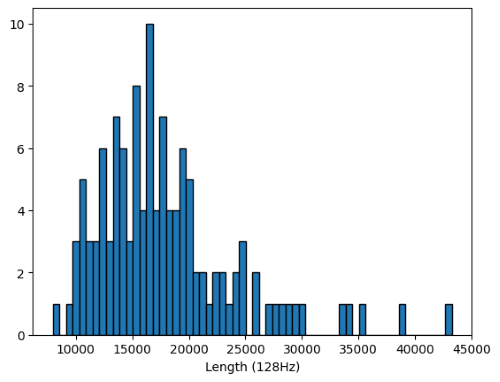
선행 연구(M. Y. Esas and F. Latifoğlu)에서는 데이터 길이를 9,250으로 고정하는 접근 방식을 제안했다. 이 방법은 여러 장점이 있다.
- 대부분의 데이터를 활용할 수 있어 데이터 손실을 최소화한다.
- 충분한 길이를 통해 신호의 맥락 정보를 더 잘 보존할 수 있다.
일부 연구(D. Tanko et al., 2022)에서는 데이터를 더 짧은 단위로 나누기도 했지만, 본 연구는 Transformer의 강점을 활용하기 위해 맥락 정보를 충분히 담을 수 있는 방식으로 데이터를 샘플링하고자 한다. 따라서 다음과 같은 방식으로 데이터를 처리했다.
- 9,250보다 짧은 데이터는 분석에서 제외한다.
- 9,250보다 긴 데이터는 9,250 단위로 나눈다. (예: 19,000 길이의 데이터는 9,250 * 2 + 500으로 나누어 2개의 subset만 사용하고, 나머지 500 길이는 버린다.)
전처리 과정을 거친 데이터는 학습 데이터와 테스트 데이터로 분리했다. 전체 데이터의 80%를 학습에, 20%를 테스트에 할당하여 총 138개의 학습 데이터와 36개의 테스트 데이터를 확보했다.
모델 설계
본 모델은 크게 Embedding과 Transformer 두 부분으로 구성되어 있다. Embedding은 Vision Transformer(A. Dosovitskiy et al., 2021)를 참고했으며, Transformer는 EEG-Transformer(Y. He et al., 2023)의 구조를 기반으로 일부 파라미터를 수정했다.
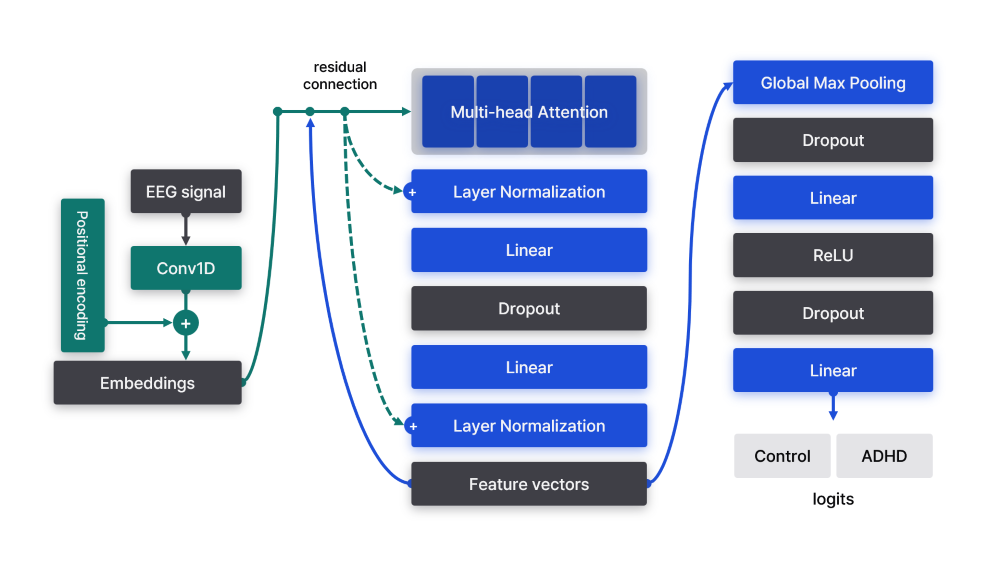
Convolutional Embedding
EEG-Transformer는 데이터 채널의 차원을 Transformer 입력 차원으로 사용하기 때문에 다른 데이터에 대해 적용이 어렵다. 특히 본 연구와 같이 채널의 크기가 작을 때 성능에 치명적인 영향을 줄 수 있다. (원본 모델은 56 채널 데이터를 사용했다.)
Vision Transformer 연구에서는 이미지 embedding에 convolution을 활용할 때 공간 정보를 효과적으로 포착할 수 있음을 보여주었다. 신호 처리 분야에서 CNN이 우수한 성능을 보이고 있다는 점을 고려해, Convolution을 이용한 Embedding layer로 데이터의 차원을 변환하는 접근 방식을 채택했다.
Embedding된 벡터($z$)는 positional encoding($E_{pos}$)과 합산된다. Positional encoding은 학습 가능한 파라미터로, 신호의 시간적 정보를 포함하기 위해 도입되었다.
\[E_x = Conv1d(x)\] \[z = E_x + E_{pos}\]기존 Vision Transformer와의 주요 차이점은 [CLS] 토큰을 사용하지 않는다는 것이다. 대신 계산된 모든 feature vector를 분류에 활용하며, 이는 EEG-Transformer의 접근 방식을 최대한 반영한 결과이다.
Attention Blocks
Embedding 벡터는 다음과 같은 구조의 Attention block으로 처리된다.
- Multi-head Attention
- Residual connection + Layer Normalization
- Linear transformation
- Dropout
- Linear transformation
- Residual connection + Layer Normalization
이 과정을 반복하여 EEG 신호의 특징을 추출한다.
Residual connection은 Attention Block의 입력($z$)을 직접적으로 더하는 과정을 의미한다.
\[x_{attn} = Attention(z)\] \[x' = LayerNorm(z + x_{attn})\]이는 모델이 원본 데이터의 특성을 잘 반영하도록 하기 위해 ResNet에서 제안한 방법이다. 원본 데이터를 더하는 identity mapping을 통해 모델 가중치를 크게 변형하지도 않아도 데이터 특성을 잘 파악하도록 도와준다.
Classifier
추출된 feature vector는 Global Max Pooling을 통해 차원을 축소한다. 이후 Feed-forward network에 입력되어 최종적으로 ADHD 여부를 분류한다.
구체적인 구현은 ViTransformer에서 확인할 수 있다.
학습
Colab 환경에서 T4 GPU로 학습을 진행했으며, 구체적인 학습 설정은 다음과 같다:
- Batch size: 8
- Gradient accumulation: 4 steps
- Cross-entropy loss
- Adam optimizer
- Learning rate: 0.001
- Linear warmup: 30 steps
- Early stopping: 30 step patience
- 5-fold cross validation
- Automatic mixed precision (FP16)
상세한 학습 과정은 ieee_transformer.ipynb에 기록되어 있다.
결과 분석
| Accuracy | Recall | F1-score |
|---|---|---|
| 0.972 | 0.952 | 0.976 |
모델은 0.972의 높은 정확도를 달성했으며, 약 30 epoch 근처에서 수렴하는 양상을 보였다.
모델 깊이
Attention block의 차원을 64-128-64로 설정하고, attention head는 4개로 구성했다. 그리고 이러한 block을 총 4번 반복했다. 더 깊은 모델 구조는 오히려 성능 저하를 야기했는데, 이는 제한된 데이터셋 규모로 인해 많은 파라미터가 완전히 학습되지 못했기 때문으로 추측된다.
Mixed Precision
Pytorch의 Auto mixed precision을 활용해 FP32와 FP16 정밀도를 혼합했다. 이 접근 방식으로 학습 속도를 약 3배 개선했으며, 최종 모델 성능에는 영향을 미치지 않았다.
한계
학습 과정에서 validation loss를 통해 모델의 과적합(overfitting) 현상을 관찰했다.
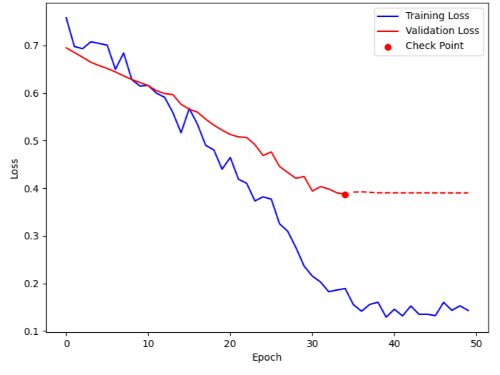
Dropout이나 weight decay와 같은 정규화 기법을 적용했음에도 불구하고 과적합 문제를 완전히 해결하지 못했다. 이는 제한된 데이터셋의 근본적인 한계로 보인다.
결론
본 연구는 Vision Transformer와 EEG-Transformer의 아이디어를 결합하여 ADHD 진단을 위한 딥러닝 모델을 제시했다. EEG 신호 분석에 Transformer 아키텍처를 적용함으로써 0.972의 뛰어난 정확도를 달성했다.
주요 의의는 다음과 같다.
- End-to-end 학습: 별도의 복잡한 전처리 과정 없이 신호의 특징을 추출했으며, 추가 데이터셋을 학습하여 모델 성능을 지속적으로 개선할 수 있다.
- 높은 성능: 0.972의 정확도와 0.976의 F1-점수를 기록하며, ADHD 진단의 가능성을 보여주었다.
- 확장성: Embedding layer 설계를 통해 다양한 EEG 데이터셋에 적용 가능한 모델 구조를 개발했다.
그러나 연구의 한계 또한 분명하다. 제한된 데이터셋으로 인한 과적합 문제는 향후 해결해야 할 중요한 과제이다. 추가 데이터 확보, 데이터 증강 기법, 보다 정교한 정규화 방법 등을 통해 모델의 안정성과 일반화 성능을 개선할 수 있을 것이다.
이 연구는 EEG를 활용한 ADHD 진단 기법을 제시함으로써, 수치 데이터를 활용한 객관적인 진단의 가능성을 보여주었다. 앞으로 더 많은 데이터를 통해 청소년 ADHD 조기 진단에 기여할 수 있을 것으로 기대된다.
참고 자료
- Y. He et al., “Classification of attention deficit/hyperactivity disorder based on EEG signals using a EEG-Transformer model,” J. Neural Eng., vol. 20, no. 5, Sep. 2023.
- M. Y. Esas and F. Latifoğlu, “Detection of ADHD from EEG signals using new hybrid decomposition and deep learning techniques,” J. Neural Eng., vol. 20, no. 3, Jun. 2023.
- D. Tanko et al., “EPSPatNet86: eight-pointed star pattern learning network for detection ADHD disorder using EEG signals,” Physiol. Meas., vol. 43, no. 3, Apr. 2022.
- A. Dosovitskiy et al., “An image is worth 16×16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2021.
- K. He et al., “Deep residual learning for image recognition,” arXiv preprint arXiv:1512.03385, 2015.
- P. Micikevicius et al., “Mixed Precision Training”, arXiv preprint arXiv:1710.03740, 2018.