Agent에게 오답노트를 시켜봤더니

Fine-tuning은 가성비가 떨어진다
A Survey on In-context Learning, 2024.
LLM은 최근 많은 분야에서 활용되고 있다. 특정 과제에서 LLM의 성능을 높이기 위해 지도학습 + 강화학습 개념의 fine-tuning 기법이 사용되고 있다. 하지만 fine-tuning은 가성비가 떨어진다. 우선, 계산 비용이 아주 비싸다. 물론 LoRA를 필두로 효율적인 학습 방법이 제안되고 있지만, LLM을 돌린다는 것만으로 엄청난 GPU 연산이 들어간다. 이렇게 학습된 모델은 특정 downstream task만 수행할 수 있다. 특정 작업은 잘 하게 되었지만, LLM이 가지는 범용성은 포기해야 한다. 뿐만 아니라 fine-tuning을 잘 하기 위해서는 많은 양질의 데이터가 필요하다. 이러한 이유들 때문에 fine-tuning을 하기가 매우 까다롭다.
따라서, fine-tuning을 하지 않고 성능을 높이는 방법이 과거부터 연구되어 왔다. 초기에는 Prompt Engineering이라는 표현을 사용하다가 어느 순간 Context Engineering이라는 표현이 나오기 시작했다. Context Engineering은 상황에 따라 입력 프롬프트를 동적으로 조절하면서 LLM의 능력을 최대한 활용하는 기법을 말한다. 최근에는 더 나아가 Context Learning까지 등장했다. Context Learning은 context에 제공되는 예시를 이용해 reasoning 하는 방법을 말한다. 파라미터를 업데이트 하지 않는다 뿐이지, 사실상 few-shot과 같은 직관을 공유한다. Learning이라고 부른 건 약간 호들갑인 거 같다
오답노트를 쓰게 하다
LLM을 사용하다보면 비슷한 실수를 반복하는 경향이 있다. 연구자들은 이 지점에 주목했다. 과거에 잘못했던 내용을 기록하고, 다음에 비슷한 상황이 왔을 때 참고하도록 한다. 아래에서 소개할 Reasoning Bank와 Training-Free GRPO는 각각 google가 tencent에서 제시한 오답노트 작성법이다. 그리고 본 글에서 소개하진 않지만 ACE라는 기법도 비슷한 맥락의 이야기를 하는 논문이다.
Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models.
Reasoning Bank
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory, 2025.
Agent memory를 통해 과거의 경험을 재활용하는 연구가 있어왔지만, 2가지 문제가 있었다.
- 기록을 쌓아둘 뿐, 추상적이고 일반화된 추론 전략을 뽑아내지 못했다.
- 과거 성공한 기록을 강조하면서, 실패에서 오는 교훈을 적절히 반영하지 못했다.
Google에서 제시한 ReasoningBank는 추상화된 전략을 찾아 기록하며, 성공했던 전략 뿐만 아니라 실패에서 얻을 수 있는 주요 전략도 함께 기억한다.
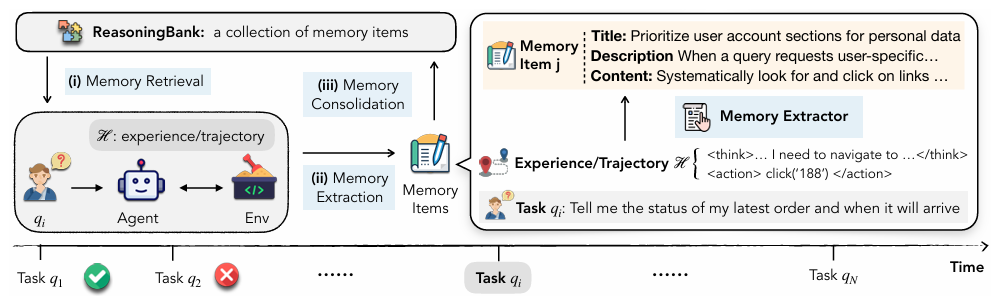
Agent는 기억 중 현재 상황과 가장 유사한 k개의 기억을 가져와 프롬프트와 함께 입력한다. Agent는 해당 프롬프트를 이용해 결정을 내리고, 이 행동의 결과에서 새로운 지식을 찾아내고, 이 지식을 title, description, content 형식으로 정리한다. 이렇게 정리된 memory item은 새로운 기억으로 추가된다.
- title: 주요 전략
- description: 한 줄 요약
- content: 경험으로부터 배운 전략과 지식
해당 논문에서 중요하게 다루는 것 중 하나가 Memory-Aware Test-Time Scaling (MATTS)이다. MATTS는 inference time에 정보를 추가로 학습하는 기법으로, Parallel Scaling과 Sequential Scaling 2가지 방법을 제안한다. Parallel Scaling은 하나의 입력 query에 대해 여러 경로를 출력하고, 공통적으로 얻을 수 있는 reasoning 패턴만 취하는 방식이다. Sequential Scaling은 하나의 경로 안에서 self-refinement를 통해 reasoning을 다듬어 가는 방식이다.
실험 결과, ReasoningBank를 사용했을 때 성능이 향상되었으며, MATTS를 적용했을 때 더 높은 성능을 보였다. 구체적으로 Sequential Scaling은 단기적인 상황에서 장점을 보였으며, Parallel Scaling은 장기적인 상황에서 장점을 보이며 더 일반화된 모습을 보였다. 또한 ReasoningBank를 적용했을 때 과제를 수행하는데 걸린 단계가 줄었는데, 이는 agent가 효율적인 reasoning 경로를 찾았음을 나타낸다.
Training-Free GRPO
Training-Free Group Relative Policy Optimization, 2025.
Tencent는 과거 경험이 마치 학습된 token prior 역할을 해 파라미터를 업데이트한 것과 유사한 효과를 낸다고 주장한다. 기존 강화학습에서 사용하던 Group Relative Policy Optimization (GRPO)의 개념을 가져와 파라미터 학습 없이 모델 성능을 개선했다. 강화학습에서의 GRPO는 입력 query에 대해 여러 출력을 생성하고, 각 출력이 독립적인 reward를 받는다. Training-Free GRPO는 동일한 아이디어를 가져와 각 출력에 성공/실패를 판단하고 하나의 공통된 원인을 요약하고 저장한다. 눈치챘겠지만 google에서 제안한 Parallel Scaling과 같은 이야기를 하고 있다.
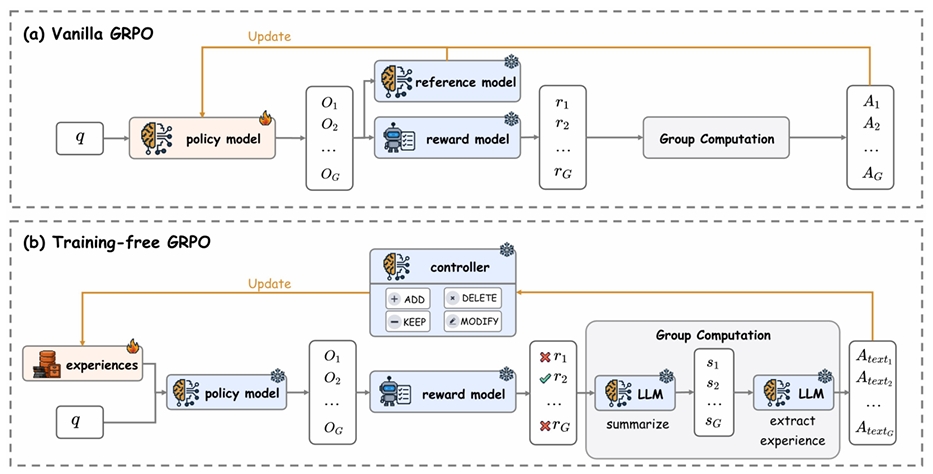
GRPO는 reward를 이용해 그룹 내에서 상대적인 advantage를 계산하고 PPO로 파라미터를 업데이트한다. Training-Free GRPO는 대신에 위 단계에서 생성된 지식을 추가함으로써 optimization을 수행한다. 이때 Add, Delete, Modify, Keep 연산 중 하나를 선택해 기억을 업데이트한다. 이 아이디어도 이전에 Long-term Memory라는 이름으로 제안되어 왔던 방법론을 응용한 것이다.
실험 결과, Training-Free GRPO는 눈에 띄는 성능 향상을 보였다. 이 방법은 올바른 reasoning을 유도했을 뿐만 아니라, agent가 적절한 tool을 사용을 하도록 가르치는 효과도 관찰되었다. 그리고 출력 그룹을 사용해 여러 경로를 생성하는 것이 하나의 출력만 생성하는 것보다 좋은 성능을 보였다.
만약 fine-tuning을 사용한다면 학습에 $10,000 정도 들었을 문제를 $18 정도로 학습해냈다. 추론 시에는 fine-tuning을 했다면 시간 당 $0.005가 들겠지만, Training-Free GRPO는 $0.02가 든다. 하지만 GPU 서버를 직접 관리할 필요 없이 분산된 LLM 서비스 인프라를 활용할 수 있기 때문에 real-world application에 더 적합할 수 있다고 주장한다.
한계점
Agent의 경험에서 중요한 지식을 찾아내 context에 주입하는 방법을 알아봤다. 하지만 이 방법도 결국 Base LLM의 추론 능력이 받쳐줘야 가능하다. 위 논문에서 사용한 LLM 모델도 Gemini-2.5-Pro, Claude-3.7-Sonnet, DeepSeek-V3.1-Terminus 등으로 기본 체급이 있는 모델들이다. 만약 reasoning 능력이 낮은 작은 모델을 사용한다면 context를 잘 관리한다해도 그 결과를 보장할 수는 없다. Gemini-2.5-flash, Qwen3-32B-Instruct 수준의 모델로 실험했을 때 성능 향상을 보였지만, 반대로 성능이 크게 떨어지는 상황도 관찰되었다.
추가로 agent 출력의 성공/실패를 판단할 때 ground truth 없이 LLM-as-a-judge를 사용하는데, 판단이 모호한 경우 해당 정보가 noise로 작용할 수 있다. 물론 실험을 통해 이러한 noise에 robust하다는 사실을 확인했지만, 여전히 발전된 judge를 적용하는 것이 과제로 남아있다.
참고문헌
- ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory, 2025.
- Training-Free Group Relative Policy Optimization, 2025.
- Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models, 2025.
- Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory, 2025.
- LoRA: Low-Rank Adaptation of Large Language Models, 2021.
- A Survey on In-context Learning, 2024.