RL Agent와 인간은 어떻게 협업해야 할까
최근 능동적으로 생각하고, 계획하고, 행동하는 Agent가 다양한 분야에서 연구되고 있다. 그리고 Agent 간의 협업을 통해 과제를 수행하는 Multi-Agent가 주목받고 있다. 관련 연구를 따라가다 보니 재밌는 직관이 생각나 글을 통해 풀어보려고 한다.
Agent 간 협업 이해하기
Improving Factuality and Reasoning in Language Models through Multiagent Debate, 2024.
Learning to Ground Multi-Agent Communication with Autoencoders, 2021.
Agent 간의 협업을 ‘인간이 해석할 수 있는가’에 따라 2가지로 나눌 수 있다.
- 자연어를 이용한 LLM 간의 소통 (NLP)
- Communication vector를 이용한 소통 (RL, Embodied)
첫번째 예시로 토론(debate)을 들 수 있다. 각 LLM이 서로의 의견을 비평하면서 주장을 다듬어가는 과정이다. 실험 결과, 하나의 agent가 생성한 답변보다 여러 agent가 반복적으로 협업할 때 더 좋은 답변을 생성했다. 이때 Agent의 모든 입출력은 자연어이다. 이해하기 쉽고 직관적이다. 하지만 이러한 소통은 비효율적이다. LLM은 자연어를 이해하기 위해 텍스트를 임베딩으로 변환해야 하며, 자연어를 출력하기 위해 벡터를 텍스트로 변환해야 한다. 만약 자연어를 입출력으로 가져야 한다는 전제 조건을 제거하면 불필요한 연산을 줄일 수 있다.
두번째 communication vector를 활용한 소통의 예시로 Embodied agent 간의 협업이 있다. 쉽게 로봇 간의 협업이라 생각해도 된다. 각 agent는 독립적으로 모델 출력을 계산한다. 여기서 출력된 vector를 서로 공유한다. 그런 다음, 공유된 vector와 본인이 출력한 vector를 고려해 행동을 선택한다 (아래 그림 참고). 매우 효율적이고, 실제로 잘 작동한다. 하지만 agent 간 어떤 메시지를 주고 받았는지 인간이 이해할 수 없다는 문제가 있다. 따라서 효율성과 이해 가능성 간의 trade-off가 있다고 할 수 있다.
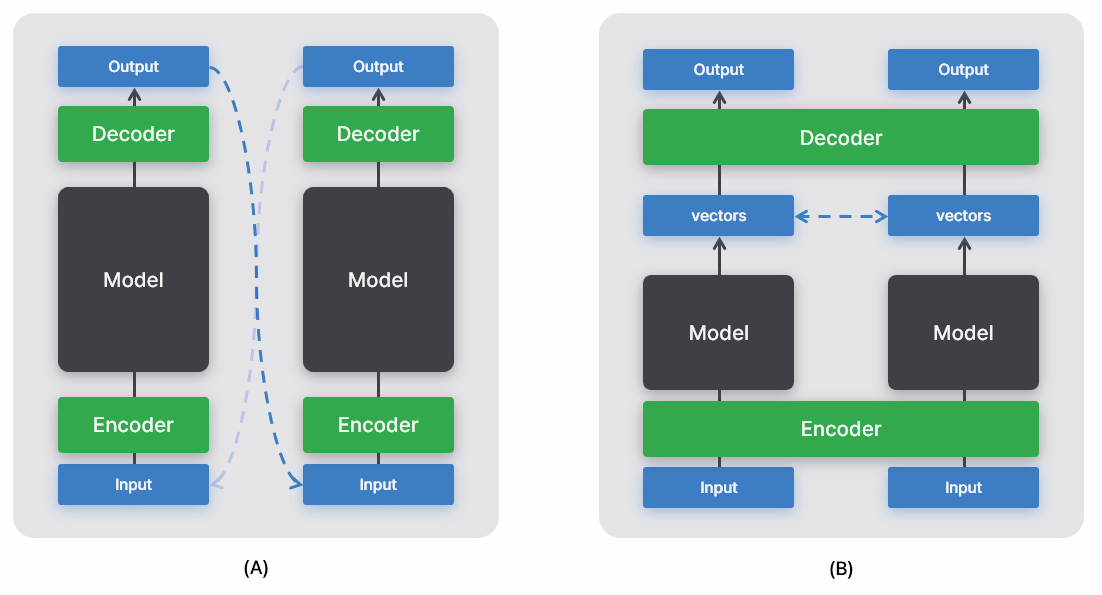
이거 멀티모달 문제 아닌가?
ImageBind: One Embedding Space To Bind Them All, 2023.
멀티모달 학습은 서로 다른 데이터를 하나의 개념으로 이해하는 학습 방법을 말한다. 예를 들어, ‘강아지’라는 텍스트, 강아지 이미지, 강아지 짖는 오디오를 동일하게 ‘강아지’라는 개념으로 인식하는 식이다. 조금 더 어렵게 이야기하면 서로 다른 모달리티의 데이터를 동일한 공간에 align하는 문제를 말한다. 많은 연구들이 멀티모달 학습이 일반화된 특징을 이해하는데 좋은 성과를 보였으며, zero-shot으로 downstream task를 푸는데 뛰어난 성능을 보인다고 보고하고 있다.
그렇다면 우리는 ‘Agent의 언어’와 ‘인간의 언어’를 서로 다른 모달리티로 정의해 이 문제를 풀 수 없을까? (Agent의 communication vector, 인간의 자연어 해석)을 pair로 정의할 수 있다면, 멀티모달 진영의 방법론을 가져와 활용할 수 있게 된다. 그리고 이러한 직관을 강화학습 관점에서 풀어낸 논문이 있어 소개한다.
LangGround 이해하기
Language Grounded Multi-agent Reinforcement Learning with Human-interpretable Communication, 2024.
MARL은 Multi-Agent Reinforcement Learning의 약자로, 강화학습 기반의 multi-agent 시스템을 뜻한다. 본 논문은 MARL의 소통을 인간이 해석 가능한 형태로 변환하는 LangGround를 제안한다. 강화학습 논문답게 문제를 decentralized partially observable Markov Decision Process: $(\mathcal{I}, \mathcal{S}, \mathcal{A}, \mathcal{C}, \mathcal{T}, \Omega, \mathcal{O}, \mathcal{R}, \gamma)$로 정의하는 단계부터 시작한다.
강화학습에 대한 배경지식이 있다고 가정하고 특징적인 notation만 몇 가지 설명하면,
- $\mathcal{I}$: set of N agent
- $\mathcal{C}$: set of communication messages
- $o_i \in \Omega$: 각 에이전트의 local observation
- $\mathcal{O}:\mathcal{S}\times \mathcal{C}\times \mathcal{I} \rightarrow \Omega$
본 문제는 agent가 협업을 통해 과제를 수행하고 얻는 보상을 최대화하는 문제로 정의한다.
\[\max_{\pi^i: \Omega \to A \times C} \mathbb{E} \left[ \sum_{t \in T} \sum_{i \in I} \gamma^t R(s_t^i, a_t^i) | a_t^i \sim \pi^i, o_t^i \sim \Omega \right]\]추가로, 중요한 개념으로 데이터 $D$가 있다. $D$는 (observation, action) pair로 정의한다. 즉, 인간이 해석 가능한 형태의 모델 입출력을 $D$로 정의한 셈이다.
모델 구조
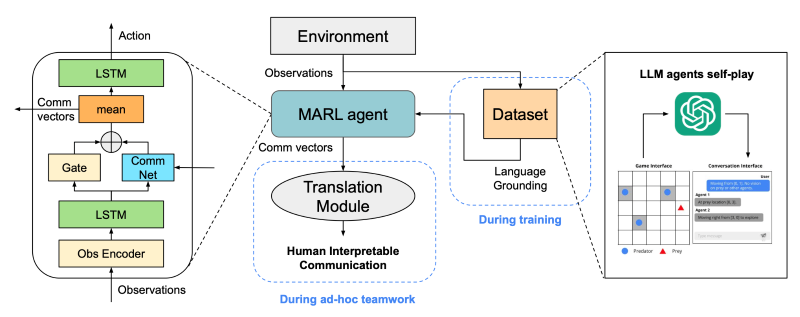
각 agent는 action과 communication vector를 출력한다. 여기서 probability gate는 communication vector를 다른 agent에게 공유할지 결정하는 역할을 한다. 공유된 communication vector는 평균으로 계산되어 다른 agent에게 나눠지며, 각 agent는 자신의 출력과 공유된 출력을 고려해 action을 선택하게 된다. 학습 효율성을 위해 Action policy와 Observation encoder는 같은 파라미터를 공유한다.
Transition Module은 학습된 agent의 communication vector를 인간이 이해가능한 데이터 $D$와 align 시키는 모듈이다. 이렇게 agent의 언어와 인간의 언어를 같은 embedding space에 위치시킴으로써 상호 변환이 가능하도록 만드는 것이다. 만약 이해할 수 없는 communication vector가 들어왔다면, 이 vector를 미리 학습시킨 공간에 매핑시킨 뒤, 가장 가까이에 있는(유사한) 데이터 $D$를 검색하면 인간이 이해가능한 형태로 메시지를 얻을 수 있다.
Loss function
\[L = L_{RL} + \lambda L_{sup}\] \[L_{\text{sup}} = \sum_{t \in T} \sum_{i \in I} [1 - \cos(c_t^i, D(o_t^i, a_t^i))]\] \[D(o_t^i, a_t^i) = \begin{cases} c_h & \text{if } (o_t^i, a_t^i) \in \mathcal{D} \\ \mathbf{0} & \text{otherwise} \end{cases}\]Loss function은 (1) $L_{RL}$: REINFORCE 알고리즘으로 gate function을 학습하는 term과 (2) $L_{sup}$: 데이터 $D$를 통해 communication protocol을 학습하는 term으로 구성된다. 식에 볼 수 있듯이 consine similarity를 이용해 agent의 언어 $c_t$와 인간의 언어 $D(o_t, a_t)$를 align 시키려는 의도를 확인할 수 있다.
실험 결과
Predator Prey, Urban Search & Rescue(USAR) 2가지 시뮬레이션 환경에서 MARL을 학습시켰다.
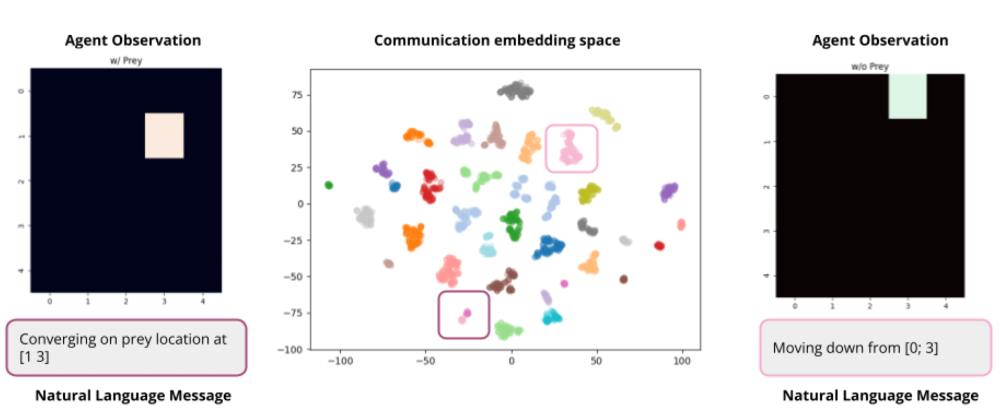
t-SNE를 통해 차원 축소한 결과를 보면, 비슷한 메시지는 가까운 공간에 위치하도록 학습된 것을 관찰할 수 있다. 추가로, vector를 “Moving down from [0; 3]”과 같이 자연어로 변환 가능함을 확인했다.
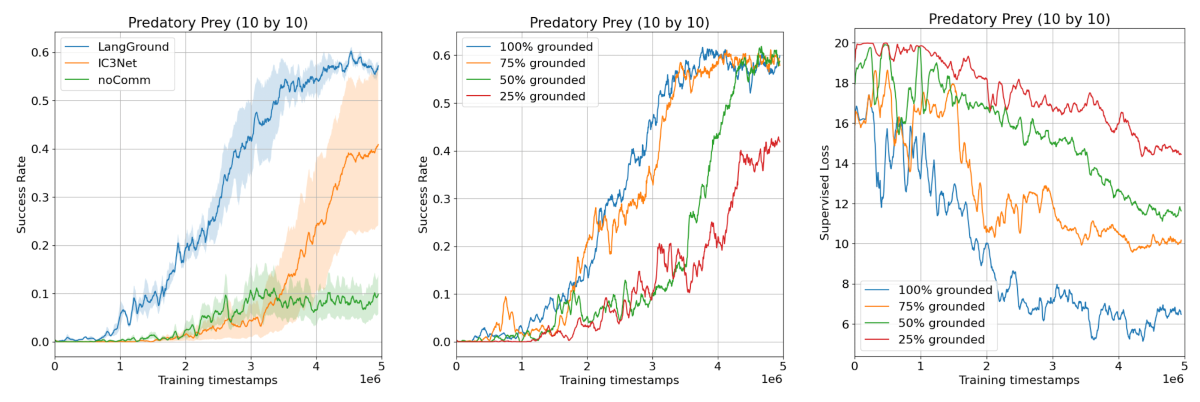
인간-agent 간의 소통 뿐만 아니라 MARL 간의 소통도 잘 학습된 것을 볼 수 있다. 소통이 없을 때(noComm)보다 소통 방식을 학습시켰을 때(LangGround) 과제 성공률이 유의미하게 높아졌다.
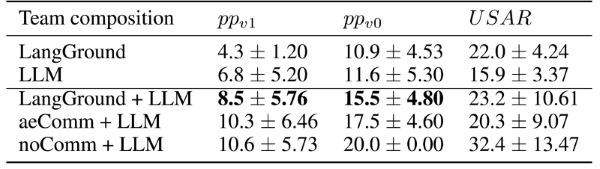
인간과의 협업 가능성을 확인하기 위해 LLM에게 인간의 역할을 부여하고 팀워크 성능을 측정했다. 과제를 성공하기까지 걸린 step을 측청했고, 이는 낮을수록 효율적인 협업이 이루어졌음을 의미한다. Agent끼리 소통했을 때 또는 LLM끼리 소통했을 때 가장 좋은 성능을 보였다. 이는 완전히 동일한 언어를 사용하는 그룹끼리의 소통이 더 효율적임을 의미한다. 하지만 다른 언어를 사용한 그룹 중에서는 LangGround를 적용한 방식이 가장 뛰어난 성적을 보였다.
추가로, LangGround는 단지 언어를 align 시키는 것 뿐만 아니라 agent의 policy 학습에도 도움이 된다고 논문에서 밝히고 있다. (이는 놀랍게도 멀티모달 연구에서의 관찰과 일치한다)
이를 통해 agent 간 소통의 효율성은 유지하면서 인간과 협업할 수 있는 가능성을 확인할 수 있었다.
참고 문헌
- Improving Factuality and Reasoning in Language Models through Multiagent Debate
- Emergent multi-agent communication in the deep learning era
- Learning to Ground Multi-Agent Communication with Autoencoders
- A Simple Framework for Contrastive Learning of Visual Representations
- ImageBind: One Embedding Space To Bind Them All
- Language Grounded Multi-agent Reinforcement Learning with Human-interpretable Communication