Multimodal Training with Tiny Reasoning
Github: Hateful-Meme
Multi-modal과 Reasoning
학기 중에 수업 기말 프로젝트로 컴퓨터비전 기술을 이용한 무언가를 만들어야 했다. 그런데 거창한 비전 모델을 학습할 GPU가 없었고돈도 없었고, 최근 논문으로만 읽었던 ‘멀티모달’과 ‘reasoning’을 모두 구현해 보면서 동시에 GPU도 적게 드는 과제를 찾다가 Facebook AI의 Hateful Memes 데이터셋을 찾게 되었다.

밈은 이미지와 텍스트를 결합해 강력한 메시지를 전달한다. 문제는 같은 텍스트라도 어떤 이미지와 결합되느냐에 따라 완전히 다른 의미를 가질 수 있다는 점이다. 예를 들어, 특정 문구가 중립적인 이미지와 함께 있으면 무해하지만, 다른 이미지와 결합되면 혐오 표현이 될 수 있다. 단순히 텍스트에 특정 단어가 있거나 이미지에 특정 객체가 있다는 표면적 단서만으로는 판단할 수 없기 때문이다. 이미지와 텍스트의 상호작용에서 발생하는 미묘한 의미를 포착해야 한다. 이 지점에서 reasoning을 적용할 가능성을 봤다. Hateful Memes 데이터셋의 핵심 특징은 Benign Confounders(양성 교란 요소)다. 이는 혐오 밈의 이미지나 텍스트를 최소한으로 변경해 비혐오 밈으로 만든 것이다. 이런 설계 덕분에 모델은 단일 모달리티에만 의존할 수 없고, 반드시 이미지-텍스트 간 상호작용을 이해해야 한다. 실험에서는 총 10,000개의 밈 중 6,800개를 학습에, 1,700개를 검증에, 500개를 테스트에 사용했다.
모델 설계
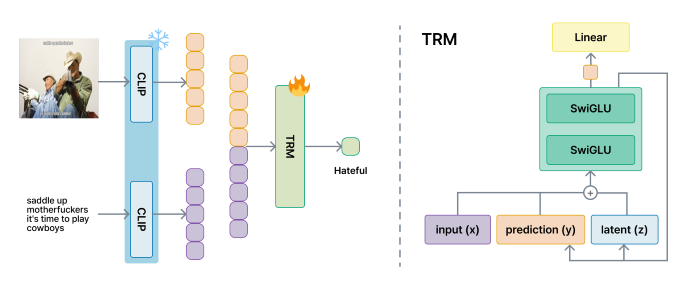
CLIP(Contrastive Language-Image Pretraining)을 백본으로 사용해 이미지와 텍스트를 각각 고차원 특징 벡터로 변환한다. CLIP은 선행 연구에서도 baseline으로 좋은 성능을 보였기 때문에 그냥 믿고 썼다. 이미지 $I$와 텍스트 $T$는 CLIP 인코더를 통해 독립적으로 처리되고, 추출된 특징 벡터들은 연결되어 통합 표현 $\mathbf{x}$를 형성한다.
단순한 FFN(FeedForward Net) 구조는 복잡한 추론에 한계가 있다. 이를 극복하기 위해 TRM(Tiny Recursive Model) 아키텍처를 도입했다. TRM은 고정된 컨텍스트 $\mathbf{x}$와 함께 두 개의 동적 상태 벡터를 반복적으로 업데이트한다:
- 예측 상태 $\mathbf{y}_t$: 최종 예측을 구체화
- 잠재 추론 상태 $\mathbf{z}_t$: 추론 과정을 심화
각 스텝에서 세 벡터를 결합하고 SwiGLU 활성화 함수를 포함한 MLP로 변환한다:
\[\mathbf{h}_t = \text{SwiGLU}(\mathbf{x} + \mathbf{y}_{t-1} + \mathbf{z}_{t-1})\]이 과정을 $N$번 반복하면서 제한된 파라미터로도 깊은 추론을 수행한다.
TRM의 핵심은 계층적 재귀 학습이다. 고정된 컨텍스트 $\mathbf{x}$와 두 개의 동적 상태 벡터 $\mathbf{y}$(예측)와 $\mathbf{z}$(추론)를 활용해 점진적으로 추론을 심화한다. 전체 프로세스는 세 단계로 구성된다.
Reasoning
1. Latent Recursion
첫 번째 단계는 추론의 기본 단위다. 컨텍스트 $\mathbf{x}$와 현재 예측 $\mathbf{y}$를 고정한 상태로, latent 상태 $\mathbf{z}$만을 $n$번 반복 업데이트한다. 이를 통해 모델은 즉각적인 답변을 내놓기 전에 문제를 충분히 생각한다.
\[\mathbf{z}^{(i)} = \mathcal{F}(\mathbf{z}^{(i-1)}, \mathbf{x} + \mathbf{y}) \quad \text{for } i=1 \dots n\]여기서 $\mathcal{F}$는 SwiGLU 블록을 포함한 TRM 네트워크다. $n$번의 추론이 완료되면, 정제된 표현 $\mathbf{z}^{(n)}$을 기반으로 예측을 한 번 업데이트한다:
\[\mathbf{y}' = \mathcal{F}(\mathbf{y}, \mathbf{z}^{(n)})\]사람이 복잡한 문제를 풀 때처럼 바로 답을 내놓지 않고, 먼저 문제를 여러 각도에서 살펴보고 내부적으로 여러 가능성을 탐색한다. 그 후에야 구체적인 답을 형성한다. Latent recursion는 이런 인간의 사고 과정을 모방한다. $\mathbf{z}$는 추론에 대한 근거를 담고 있는 공간이고, $\mathbf{y}$는 구체화된 답변이다.
2. Deep Recursion
두 번째 단계는 메모리 효율성을 유지하면서 추론 깊이를 늘리는 전략이다. Latent Recursion 블록 전체를 $T$번 실행하고, 처음 $T-1$번은 그래디언트 계산을 비활성화한다. 마지막 $T$번째 반복에서만 그래디언트를 계산한다. 일반적인 딥러닝에서는 역전파를 위해 모든 중간 계산 결과를 메모리에 저장해야 한다. $T$번의 재귀를 모두 역전파하면 메모리 사용량이 선형으로 증가한다. 하지만 처음 $T-1$번을 추론 전용으로 실행하면 중간 활성값을 저장할 필요가 없다. 이를 통해 깊은 추론 그래프를 유지하면서도 역전파 오버헤드를 대폭 줄일 수 있다. 실험에서 $T=3$을 사용했다. 이는 각 감독 단계마다 실제로는 9번($n \times T = 3 \times 3$)의 잠재 업데이트가 일어나지만, 메모리는 3번의 재귀만큼만 사용한다는 뜻이다. 제한된 GPU 메모리로도 깊은 추론이 가능해진다.
3. Deep Supervision
세 번째 단계는 학습 안정성을 보장하는 supervision 전략이다.
- 전체 추론 과정을 $N_{sup}$개의 supervision 단계로 나눈다.
- 각 supervision 단계 $k$마다:
- 컨텍스트 $\mathbf{x}$는 그대로 유지
- 이전 단계의 $\mathbf{y}$와 $\mathbf{z}$를 초기 상태로 재사용
- Deep Recursion을 수행해 새로운 예측 $\hat{\mathbf{y}}_k$를 생성
- 즉시 손실을 계산하고 역전파 수행
- $\mathbf{y}$와 $\mathbf{z}$를 계산 그래프에서 분리(detach)
이 방식은 순환 신경망의 Truncated Backpropagation Through Time과 유사하다. 매우 긴 시퀀스를 학습할 때, 전체 시퀀스에 대해 역전파하면 그래디언트 소실/폭발 문제가 발생한다. 대신 시퀀스를 짧은 구간으로 나누고 각 구간마다 독립적으로 역전파한다. Deep Supervision도 마찬가지로 긴 재귀 체인을 supervision 단계로 나누어 안정적인 학습을 가능하게 한다.
전체 학습 과정에 대한 수도 코드는 다음과 같다.

실험 결과
| 모델 | AUC | Accuracy | F1 |
|---|---|---|---|
| ViLBERT CC | 70.8 | 70.4 | - |
| Visual BERT COCO | 73.7 | 70.8 | - |
| VILIO | 81.6 | - | - |
| Visual BERT | 75.2 | 71.0 | - |
| UNITER | 79.1 | - | - |
| CLIP + MLP (Ours) | 82.6 | 75.4 | 65.8 |
| CLIP + TRM (Ours) | 81.9 | 72.7 | 67.6 |
CLIP + MLP는 AUC 82.6과 정확도 75.4%로 최고 성능을 달성했다. CLIP + TRM은 AUC 81.9, 정확도 72.7%로 약간 낮지만, F1-score에서 67.6으로 1.8%p 향상을 보였다. 이는 재귀적 추론이 클래스 경계 근처의 애매한 케이스를 더 정교하게 탐색하고, 정밀도와 재현율을 균형있게 개선함을 의미한다. 레이블 불균형과 미묘한 의미 해석이 중요한 혐오 밈 탐지에서 F1-score 개선은 특히 의미있다.
TRM이 전체 AUC와 정확도에서 단순 MLP를 일관되게 능가하지 못한 이유는 입력 표현의 맥락 부족으로 보인다. TRM은 CLIP이 추출한 고정 컨텍스트 $\mathbf{x}$를 기반으로 추론하는데, CLIP은 주로 지각적, 어휘적 상관관계를 학습했다. 현대 사회 이슈, 역사적 참조, 정치적 사건, 문화적 고정관념 등 고맥락 지식이 필요한 밈은 특징 추출 단계에서 충분히 인코딩되지 않을 수 있다. 이런 경우 재귀적 추론은 불완전한 맥락에서 작동해 반복적 추론의 장점을 충분히 활용하지 못한다. 그럼에도 TRM의 F1-score 개선은 재귀적 추론이 더 균형잡힌 의사결정에 기여함을 보여준다. 관련 정보가 존재할 때 미묘한 구분을 정제하는 능력이 있지만, 중요한 외부 맥락이 입력 공간에 없으면 어려움을 겪는다.
비록 실험 결과가 예상대로 깔끔하게 나오진 않았지만, multimodal + reasoning을 모두 구현하고 학습까지 경험해 봤다는 점에서 재밌는 실험이었다.