역방향으로 미분값 계산하기
딥러닝으로 모델을 학습시키기 위해 미분 값을 구하는 과정이 필요하다. 만약 왜 미분이 필요한지 모른다면 ‘경사하강법과 학습률‘을 참고하면 된다. 해당 내용을 몰라도 이번 글을 이해하는 데는 문제는 없다.
배경 지식
- 미분의 정의 (+극한)
- 도함수
- 합성 함수 표현
문제점
일반적으로 미분 값을 구할 때, 도함수를 구한 후 값을 대입해 계산한다.
하지만 문제는 모델의 연산 과정이 너무 복잡하다.
\[f(x)=Linear(Droupout( ... (maxpool(relu(conv(...))))))\]위 예시는 아주 기본적인 CNN 모델의 일부이다. 그리고 가장 많이 사용되는 손실 함수인 Cross Entropy with Softmax는 아래와 같이 정의된다.
위 모델을 $f(x)$라고 할 때, $H(x, y)$에 $f(x)$를 대입하고 도함수를 구한다고 생각하면 막막하다. 나는 할 자신이 없다. 도함수를 구하는 것이 매우 복잡하고 비효율적이다. 이러한 문제를 해결할 수 있는 아이디어로 Chain-Rule이 있다.
Chain-Rule
미분 값을 구하는 과정을 이해하기 위해서는 연쇄 법칙이라고 부르는 Chain-Rule에 대한 배경 지식이 필요하다.
결론부터 이야기하면 연쇄 법칙은 분수를 약분하듯이 분자, 분모가 연쇄적으로 계산된다는 법칙이다. 여기까지만 알아도 미분값을 구하는 데는 문제가 없다. 그래도 확실히 하기 위해 조금 더 자세히 이야기해 보겠다. 합성 함수를 미분하기 위해 연쇄 법칙을 적용해 보자.
\[y=f(g(x))=f\circ g(x) \\ g(x)=u\to f(u)=y\]미분 가능한 함수 $f$와 $g$에 대해 위와 같은 관계가 성립한다고 하자.
\[\cfrac{dy}{du}=\displaystyle\lim_{\triangle u\to0}\cfrac{\triangle y}{\triangle u}\]미분의 정의를 활용해 작성한 식이다. 여기서 $u$와 $x$의 관계를 살펴보자.
\[\triangle u=g(x+\triangle x)-g(x)\] \[\triangle x\to0\ \ \text{then}\ \ \triangle u \to0\]$u$의 변화량은 $g(x)$의 변화량을 뜻한다. $x$의 변화량이 0에 가까워지면 $u$의 변화량도 0에 가까워진다. 따라서 $\cfrac{dy}{du}$를 다시 정의하자.
\[\cfrac{dy}{du}=\displaystyle\lim_{\triangle u\to0}\cfrac{\triangle y}{\triangle u}=\displaystyle\lim_{\triangle x\to0}\cfrac{\triangle y}{\triangle u}\] \[\cfrac{du}{dx}=\displaystyle\lim_{\triangle x\to 0}\cfrac{\triangle u}{\triangle x}\]이제 구해둔 단서를 연결해 보자.
\[\cfrac{dy}{du}*\cfrac{du}{dx}=\displaystyle\lim_{\triangle x\to0}\cfrac{\triangle y}{\triangle u}*\displaystyle\lim_{\triangle x\to0}\cfrac{\triangle u}{\triangle x}\\=\displaystyle\lim_{\triangle x\to0}(\cfrac{\triangle y}{\triangle u}*\cfrac{\triangle u}{\triangle x})\\=\displaystyle\lim_{\triangle x\to0}\cfrac{\triangle y}{\triangle x}\\=\cfrac{dy}{dx}\]극한 값의 특징을 이용해 연쇄 법칙을 확인할 수 있다. 그리고 합성 함수의 미분 값을 여러 미분 값으로 쪼갤 수 있다는 것도 알 수 있다.
그렇다면 앞에서 봤던 모델의 미분도 연쇄 법칙을 이용해 쪼개볼 수 있다.
$y=maxpool(relu(conv(x)))=maxpool\circ relu\circ conv(x)$
위와 같은 합성 함수의 연산을 아래와 같이 표현할 수 있다.
$conv(x)=z_0\to relu(z_0)=z_1\to maxpool(z_1)=y$
$\cfrac{dy}{dx}=\cfrac{dy}{dz_1}\cfrac{dz_1}{dz_0}\cfrac{dz_0}{dx}$
그리고 각각의 함수는 덧셈, 곱셈, 제곱, log, sin, cos 등등 작은 단위의 연산으로 쪼갤 수 있다. 따라서 우리는 작은 단위의 연산에 대해 미분 값을 정의하면, 커다란 함수의 미분값도 계산할 수 있게 된다.
연산자와 미분 결과
다양한 연산이 있지만 이번 글에서는 가장 기본적인 덧셈(+), 뺄셈(-), 곱셉(*), 제곱(^2)의 미분 값만 살펴보겠다.
덧셈, 뺄셈
$\cfrac{d}{da}(a+b)=1$, $\cfrac{d}{da}(a-b)=1$
덧셈과 뺄셈은 어떤 값이 더해지던 항상 미분 값은 1이다.
곱셈
\[\cfrac{d}{da}(a*b)=b\]a에 대한 미분값으로 b가 나왔다. 즉, 곱해진 값을 미분 값으로 갖는다는 것을 알 수 있다.
제곱
\[\cfrac{d}{da}a^2=2a\]제곱은 알다시피 2를 곱한 값을 미분 값으로 갖는다.
순방향 계산 (forward)
계산되는 과정을 확인하기 위해 간단한 식을 하나 만들어보자.
\(L=(wx+b-y)^2\)
$wx+b$라는 일차 함수와 $y$의 차이를 제곱한 값을 $L$이라고 두었다. 이제 위 식의 계산 과정을 단계별로 생각해 보자. 먼저 $w$와 $x$를 곱하고, $b$를 더한 후, $y$를 뺀다. 마지막으로 제곱을 한다. {x=4, w=1, b=-3, y=3}일 때, 과정을 그림으로 표현하면 아래와 같다.
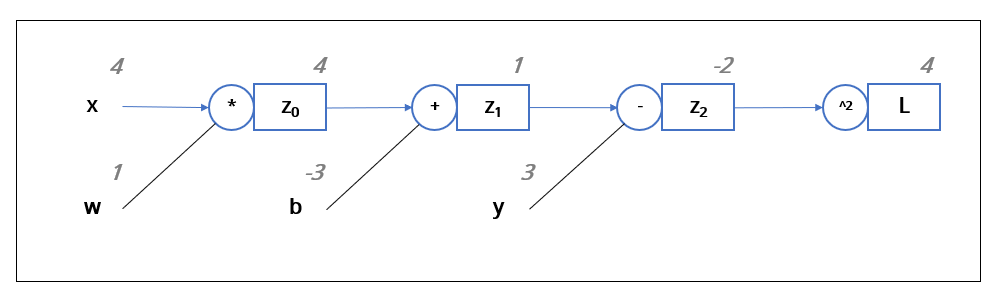
왼쪽부터 순서대로 값과 연산자를 거쳐 최종적으로 $L$이 계산된다. 그리고 계산된 각각의 결괏값을 저장해뒀다.
역방향 계산 (backward)
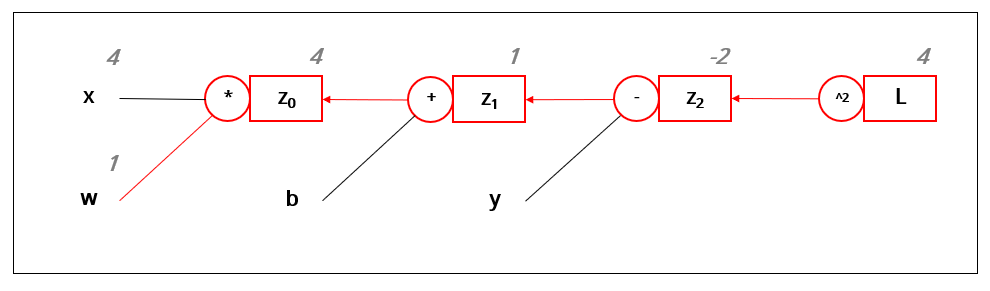
앞에서 봤던 연쇄 법칙을 이용해 \(\cfrac{dL}{dw}\)를 정의했다.
그럼 이제 하나씩 찾아가 보자.
\[\cfrac{dL}{dz_2}=2z_2\]$L$은 제곱(^2)으로 계산되었다. 위에서 제곱은 2를 곱한 값을 미분 값으로 갖는 것을 확인했었다.
$z_2$는 뺄셈(-)으로 계산되었다. 뺄셈은 항상 1을 미분 값으로 갖는다.
$z_1$은 덧셈(+)으로 계산되었고 덧셈도 항상 미분 값으로 1을 갖는다.
$z_0$는 곱셈(*)으로 계산되었다. 따라서 곱해진 값인 $x$를 미분값으로 갖는다. ($z_0 = wx$)
결과적으로 $w$에 대한 $L$의 미분 값은 -16으로 나온다. 순방향으로 계산하는 과정에서 $z_2$의 값을 저장해 두었기 때문에 별다른 연산 없이 바로 결과를 구할 수 있었다. 따라서 순방향으로 한 번, 역방향으로 한 번 계산하고 나면 미분값을 구할 수 있다.
직접 손으로 도함수를 계산해 미분 값을 구해도 동일한 결과가 나오는 것을 확인할 수 있다.
역전파 (BackPropagation)
우리가 했던 거꾸로 계산했던 과정이 역전파의 아이디어이다. 역전파 알고리즘은 모든 신경망 학습에 사용되는 핵심적인 개념이다.
1
2
# Pytorch
loss.backward() # 역방향으로 계산
자세한 내용이 궁금하면 Pytorch: autograd에 대해 찾아보면 알 수 있다.