FastAPI 기반 딥러닝 모델 API 구축하기
항상 공부를 하면서 궁금한 점이 있었다. 내가 만드는 기술이 사용자에게 닿기까지 어떤 과정이 있을까? 머신러닝 모델을 공부하면서도 같은 의문이 들었다. 그래서 이미지 파일을 받아 딥러닝 모델로 예측하는 API를 만들어 보았다.
Github: serve-models
Model 학습
모델과 데이터셋을 고르는 기준은 단순하다. 로컬에서 가볍게 돌릴 수 있어야 한다. 지금은 모델이 중요한 게 아니라 그럴싸한 API를 만드는 것이 목표이기 때문에 성능보다 속도를 우선시했다. 데이터셋은 가벼운 Fashion MNIST를 사용했다. 28 x 28의 작은 크기 덕분에 빠르게 학습할 수 있다.
참고로 Fashion MNIST는 부츠, 운동화, 티셔츠, 가방 등 의류 이미지로 구성된 데이터셋이다.

데이터 정규화
Pytorch에서 제공하는 사전학습 모델 중 가장 가벼운 MobileNet_v2를 사용했다.
먼저 의문이 든 부분은 정규화 방식이었다. 본 모델은 흑백 이미지를 사용하기 때문에 각 채널에 같은 평균과 표준편차를 주는 게 맞다고 생각했다. 그런데 사전학습된 원본 모델은 각 채널에 다른 평균과 표준편차를 사용한다. 학습된 모델 파라미터를 활용하기 위해서는 원본 모델이 사용한 정규화 방식을 그대로 사용해야 할 것도 같다. 구글링을 해보니 이 부분에 대해서 의견이 다양했다. 그래서 같은 조건[batch: 64, learning rate: 0.005] + Early stopping을 적용해 정규화 결과를 비교해 보았다.
- 원본 모델의 정규화 방식: accuracy 91.75%
- 같은 값을 모든 채널에 적용: accuracy 89.15%
유의미한 결과라고 확신할 수 없지만 원본 모델의 정규화가 더 좋은 성능을 보였다.
MobileNet_v2 학습
데이터는 Pytorch 문서에 따라 사전 학습 데이터와 동일한 정규화를 진행한다.
1
2
3
4
5
6
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=3),
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
학습: final.ipynb
- Training set: 54000 (90%)
- Validation set: 6000 (10%)
- Test set: 10000
- Batch: 32
- Learning rate: (1차) 0.003, (2차) 0.001
- Epoch: (1차) 10, (2차) 7
- Optimizer: Adam
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
##### 1차 #####
[1] Train: 0.38468 | Validation: 0.29368
[2] Train: 0.27225 | Validation: 0.24403
...
[10] Train: 0.13610 | Validation: 0.17212
Accuracy 93.01
##### 2차 #####
[1] Train: 0.09615 | Validation: 0.07122
...
[6] Train: 0.05107 | Validation: 0.06074
[7] Train: 0.04638 | Validation: 0.06033
[8] Train: 0.04151 | Validation: 0.06148
[9] Train: 0.03675 | Validation: 0.06153
EarlyStopping: [Epoch: 7]
Accuracy: 94.36
옷장에서 사진을 몇 장 찍어 테스트 했다.

대부분 잘 예측했다. 비록 부츠를 운동화라고 농담도 하지만 API 만드는 연습을 하기에는 그럴싸한 모델이라고 판단했다.
FastAPI
API를 생성하기 위해 기존에 작성했던 Flask 코드를 바탕으로 코드를 완성했다. 그런데 Flask에 대해 찾아보다보니 틈틈히 FastAPI가 보였다. FastAPI 소개 영상에는 FastAPI를 찬양하는 댓글이 많았고, 궁금해서 이번 기회에 사용해 보았다. 결론만 말하면 마음에 들었다. 이유는 다음과 같다.
- 데이터 검증이 쉽다. 타입 힌트를 이용해 입력 타입을 강제할 수 있다.
- 자동 생성된 /docs를 통해 POST 요청을 쉽게 보낼 수 있다.
- 속도가 빠르다. 필자가 체감할 수준은 아니지만 여러 지표가 그렇게 말하고 있다.
- 쉽다. 벡엔드를 잘 모르는 필자도 쉽게 짤 수 있었다.
API 구현
목표는 사용자로부터 이미지를 입력받아 모델 추론 결과를 돌려주는 API이다.
1
2
3
4
5
6
7
8
@app.post("/fashion-mnist")
async def predict_fashion(file: UploadFile = File()):
file = await is_valid_size(file)
file = await is_valid_image(file)
img_tensor = convert_image(file.file)
label, probs = predict(img_tensor)
return {"label": label, "probs": probs}
Request로 테스트
Python을 통해 요청을 날려봤다.
코드: server/test.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import requests
port = "8000"
url = f"http://127.0.0.1:{port}/fashion-mnist"
images = [f"./static/sample/{name}.png" for name in ("Sneaker", "Trouser")]
for img in images:
with open(img, "rb") as image_file:
# { Field-name: File-name, File-object, File-type }
files = {"file": (img, image_file, "image/png")}
response = requests.post(url, files=files)
resp_json = response.json()
print("Status:", response.status_code)
print("Response:", resp_json)
assert response.status_code == 200
1
2
3
4
Status: 200
Response: {'label': 'Sneaker', 'prob': 0.8817731738090515}
Status: 200
Response: {'label': 'Trouser', 'prob': 0.9963659048080444}
원하는 결과를 잘 받아왔다. 코드로 주고 받는 방식은 결과를 받아와 추가적인 작업을 진행할 수 있다. 결과를 바탕으로 데이터 분석 등을 수행한다면 템플릿보다 유용한 방법이다.
FrontEnd에서 요청
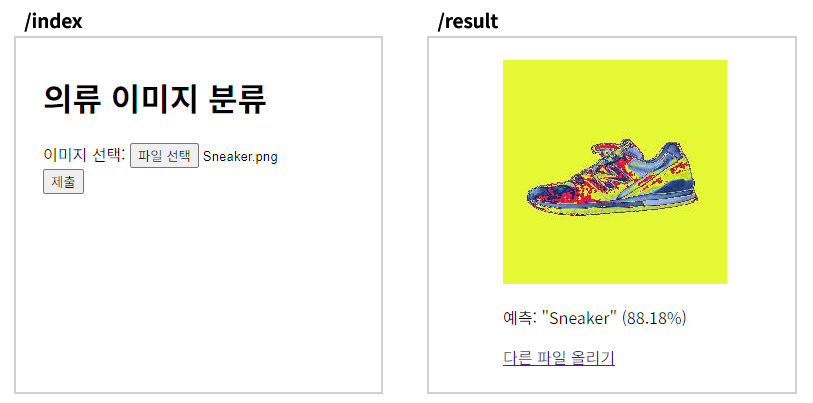
수정: 25-03-01
위 사진을 보면 예상한대로 잘 작동하는 것처럼 보인다. 이렇게 템플릿을 활용하면 코드를 잘 모르는 사람도 이미지를 넣어보고 테스트할 수 있는 환경이 만들어진다.
Docker
마지막으로 완성한 API를 실행할 Docker 환경을 구축했다.
Dockerfile 원본: Dockerfile
1
2
3
4
5
6
7
8
9
10
FROM python:3.10-slim
# 생략...
RUN pip install torch==2.5.1 --index-url https://download.pytorch.org/whl/cpu
RUN pip install torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cpu
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host=0.0.0.0", "--port=8000"]
처음에는 평범하게 torch와 torchvision을 설치했다. 그랬더니 도커 이미지 크기가 10G를 넘어갔다. 그런데 어차피 모델을 CPU에서 돌릴 거라면 CUDA 관련 라이브러리는 설치할 필요가 없다. 그래서 whl/cpu를 통해 CPU 버전을 설치했더니 용량이 1.8G로 눈에 띄게 줄었다.
컨테이너 외부에서 접속할 수 있도록 host는 0.0.0.0으로 열어주었고, port는 도커 EXPOSE와 동일하게 설정했다.
1
2
docker build -t app:0.1 .
docker run -p 8080:8000 --name test app:0.1
빌드하고 실행해보면 위에서 봤던 것과 같이 POST 요청을 잘 처리한다.
모델 학습부터 사용자에게 전달하는 과정을 살펴보았다.
*여담으로 Github에 가면 버려진 파일이 있다. 원래는 모델 학습에서 보여줬던 실험을 로컬에서 MLFlow를 사용해 돌릴 계획이었다. 그런데 base 모델을 학습해보니 생각보다 시간이 오려 걸렸고, 결국 Colab의 도움을 받았다.
(추가) 풀스택으로 챗봇 구현
(2025.06.06) 학교 과제를 하며 본 프로젝트와 같이 프론트엔드 + 백엔드를 모두 구현해야 하는 상황이 생겼다. 이 경험을 바탕으로 챗봇 UI를 구현하고, 백엔드는 FastAPI로 간단한 POST 요청을 구현했다.
코드: skku-swe2025
미리 공부한 덕분에 크게 시간을 들이지 않고 빠르게 구현할 수 있었다.