영상을 통한 우울증 예측 모델 분석
동기
성균관대 우수학부생 프로그램을 통해 우울증 챗봇 개발에 참여하는 기회를 얻었다. 이전에 실시간 얼굴 인식 프로젝트를 진행한 경험이 있어 얼굴 이미지를 통해 우울증을 탐지하는 멀티모달 구현에 도전했다.
논문 요약 (번역/ 정리)
이미지를 중심으로한 우울증 연구 중 논문: Automatic Depression Detection via Learning and Fusing Features from Visual Cues을 찾게 되었다.
문맥을 위해 일부 표현이 의역됐으며, 혼동의 여지가 있을 경우 영문과 번역을 함께 작성했다. 기술 용어는 혼동이 없도록 원문으로 작성했다.
( + 오역이 있다면 댓글로 알려주세요!)
Abstract
In this paper, we propose a novel Automatic Depression Detection (ADD) method via learning and fusing features from visual cues. Specifically, we firstly construct Temporal Dilated Convolutional Network (TDCN), in which multiple Dilated Convolution Blocks (DCB) are designed and stacked, to learn the long-range temporal information from sequences. Then, the Feature-Wise Attention (FWA) module is adopted to fuse different features extracted from TDCNs.
이 논문에서 우리는 학습을 통한 자동 우울증 탐지(ADD)와 시각 정보를 융합하는 방법을 제안한다. 먼저, Temporal Dilated Convolutional Network(TDCN)이 있다. TDCN은 여러 Dilated Convolution Blocks(DCB)이 겹쳐 있는 형태로 연속된 정보로부터 맥락을 학습할 수 있다. 그리고 Feature-Wise Attention(FWA)이 적용되어 여러 TDCN에서 추출된 특징을 연결할 수 있다.
Introduction
과거 우울증 진단은 Eight-item Patient Health Questionnaire depression scale(PHQ-8) 같은 방식을 사용했으며, 전문가의 주관적인 견해가 반영된다. 하지만 ADD는 언어/ 시각 정보를 바탕으로 보다 객관적인 판단을 내릴 수 있다.
우울증 환자는 멍한(glazed) 표정이나 특징적인(abnormal) 얼굴 움직임을 가지고 있다. 하지만 즉시 이러한 특징을 보이지는 않는다. 대신 비교적 긴 시간을 관찰해야 알아챌 수 있다. 따라서 시각 정보로 우울증을 탐지하기 위해서는 시간(temporal) 정보를 다루는 과정이 필요하다. 선행 연구에서 LSTM과 TCN을 활용했지만 여전히 장기(overlong sequences) 정보를 충분히 고려하지 못했고, 단일 시각 정보를 활용함으로서 복합적인 시각 단서를 반영하지 못했다.
이 연구는 크게 Temporal Dilated Convolutional Network(TDCN)과 Feature-Wise Attention(FWA) 두 종류의 모듈로 구성되어 있다. TDCN은 dilated convolution 연산을 통해 우울증 정보를 추출한다. FWA는 각 특징 채널(feature channels)에 다른 가중치를 부여해 탐지된 특징을 강화한다.
- TDCN은 긴 영상에서 시간(temporal) 정보를 효과적으로 추출해낸다. TDCN 내에는 두 개의 평행한 dilated convolution 모듈이 적용되어 우울증 탐지에 필요한 유용한 정보를 학습하도록 했다.
- FWA 모듈은 TDCN branch로부터 학습된 정보를 융합하기 위해 설계했다. Attention 모듈은 더 중요한 정보를 강조해 ADD의 정확도를 높인다.
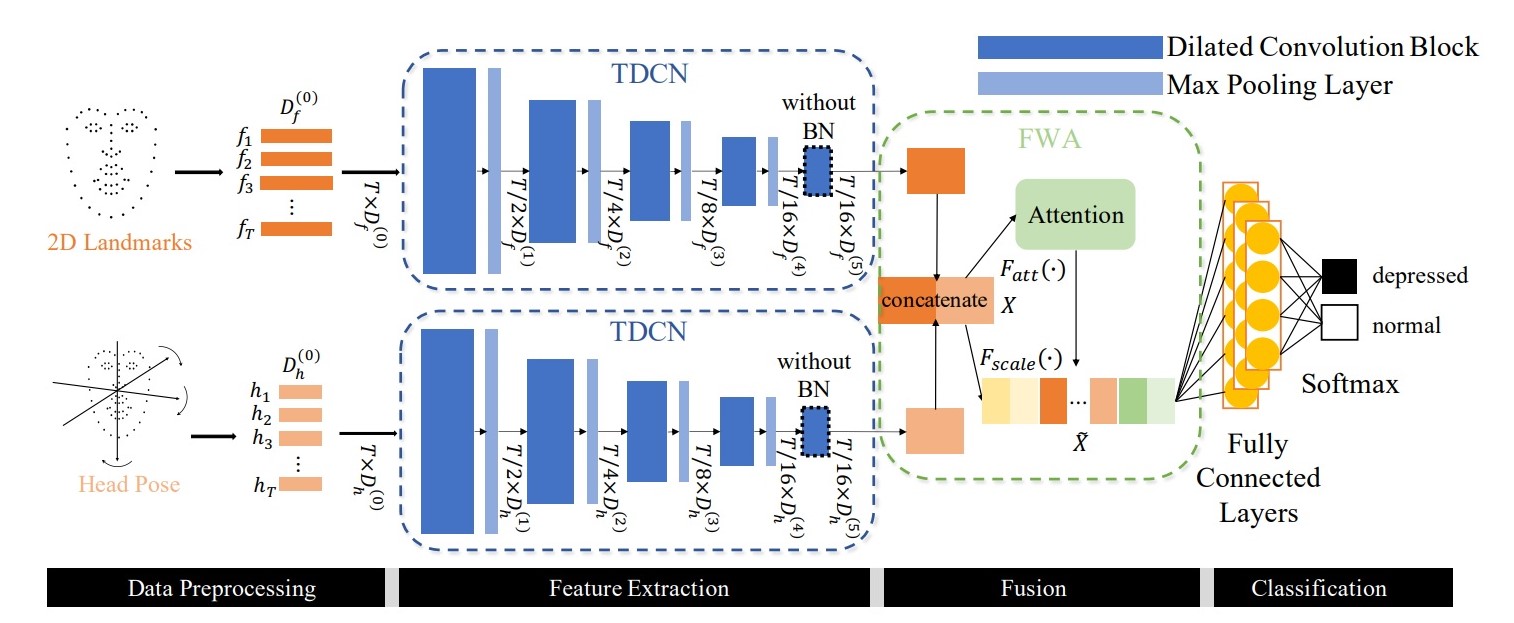 Fig. 1
Fig. 1
Temporal Dilated Convolution Network
TDCN은 일반적으로 multi-layer로, 하나의 layer는 5개의 Dilated Convolutional Blocks(DCB)과 4개의 Max-Pooling layers로 구성된다. 각 TDCN 층의 DCB는 다른 범위의 지각 정보(perceptive ranges)를 탐색한다. 그리고 TDCN 파이프라인에서 Max-Pooling 층은 계속해서 특징의 크기(resolution)를 줄여나가며 중요 반응을 점진적으로 추출한다.
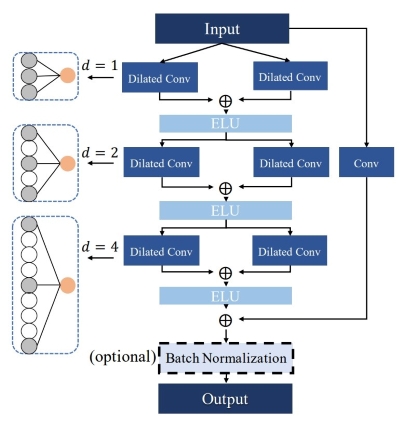 Fig. 2
Fig. 2
Fig 2는 평행한 두 dilated convolution이 어떻게 구성되어 있는지 볼 수 있다.
- 입력: $ X=[x_1;x_2;…;x_T]\in \mathbb{R}^{T\times D} $
- $ T $: 시간(time step)
- $ D $: 특징의 차원
dilated convolution은 아래와 같이 표현된다.
\[F(t)=\sum_{i=0}^{k-1}filter(i)\cdot x_{t+d\cdot (i-1)}+b\]$ d $는 dilation factor, $ k $는 kernel 크기, $ b $는 편향(bias)이다. 입력과 출력의 크기를 맞추기 위해 Zero-Padding이 적용됐다. dilation factor는 2배씩 증가하며 다른 범위(time spans)에서 시간(temporal) 정보를 얻는다. 다른 dilaton 인자 사이에는 합의 평균과 ELU가 적용된다.
\[f_{ELU}(x)=\left \lbrace \begin{matrix} x & \text{if } x\geq 0 \newline e^x-1 & \text{if } x<0 \end{matrix}\right.\]네트워크가 깊어지며 발생하는 degradation 문제를 피하기 위해 추가(residual) 블록을 추가했다. 다음 단계에서 요소별(element-wise) 덧셈을 수행하기 위해 kernel 크기가 1인 1D convolution 층을 모든 DCB에 추가했다. DCB의 마지막에는 batch 정규화를 통해 학습을 가속화했지만, gradient vanishing 문제가 발생할 수 있다. 따라서 다른 분포의 특징을 남겨두기 위해 TDCN의 마지막 DCB에서는 정규화 층을 제거했다.
마지막 TDCN을 제외한 모든 DCB 뒤에 max-pooling 층을 추가했다. 이는 출력 tensor가 더 넓은 범위를 수용해 중요한 장기(long sequence) 정보를 모은다. 또한 sequence의 길이를 줄여 모델의 복잡도를 줄이는 역할도 한다.
Feature-Wise Attention
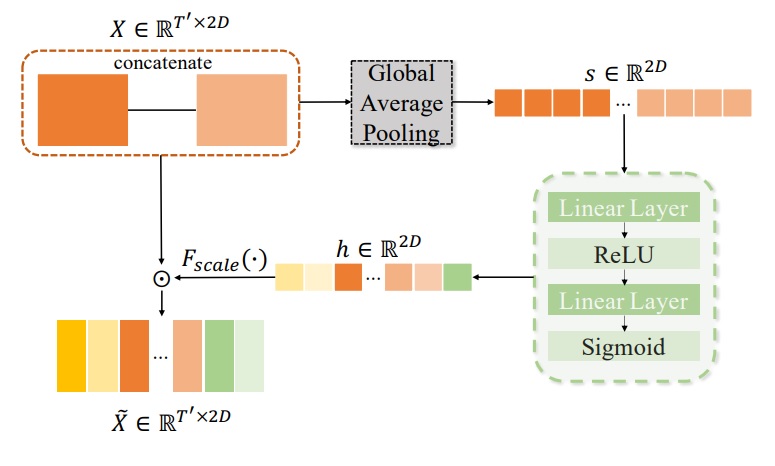 Fig. 4
Fig. 4
FWA는 다른 종류의 시각 정보를 효과적으로 합치기 위해 설계됐다. 먼저 다른 TDCN branch에서 학습된 특징을 직접적으로 연결(concatenate)해 $ X\in \mathbb{R}^{T\times kD} $를 도출한다. 여기서 $ D $는 특징의 차원, $ k $는 TDCN brach의 개수다. 본 연구에 $ k $는 2이다. 그 다음, global average pooling이 적용돼 특징별 벡터 $ s\in \mathbb{R}^{kD} $를 얻는다. global average pooling은 아래와 같이 정의된다.
여기서 $ x_{i,j} $는 i번째 time step & j번째 특징 차원의 $ X $을 나타내는 단위이다. 그 후 2개의 Linear 층과 ReLU가 $ s $에 적용된다. 최종적으로 sigmoid가 적용되며 결과인 $ h\in \mathbb{R}^{kD} $는 특징 채널의 중요도를 나타낸다.
\[h=\sigma_{sigmoid}(W_2(f_{ReLU}(W_1s)))\] \[\tilde{X}=F_{scale}(x,h) =X \odot \tilde{H}\]$ h $를 $ X $와 같은 크기로 broadcast 시킨 다음 요소별 곱(element-wise product)을 통해 결과를 도출한다.
데이터
데이터는 Distress Analysis Interview Corpus Wizard-of-Oz dataset (DAIC WOZ)를 사용했다. DAIC는 오디오, 영상 그리고 오디오를 받아쓴 필기본(transcript)을 가지고 있다. training/validation/testing 크기는 각각 107/35/47이다. 본 연구는 모든 샘플의 길이를 5000으로 다듬어 사용했다. 시각 정보는 OpenFace toolkit으로 추출된 68개의 2D/3D 얼굴 랜드마크, Action Units(AUs), 주시(gaze) 정보, 얼굴 방향(head-pose) 그리고 Histogram of Oriented Gradients(HOG) 특징이다. 본 연구는 2가지 특징을 사용해 모델의 성능을 측정했다. 참고로 3개 또는 그 이상의 정보를 사용해 봤지만 탐지 성능이 크게 향상되지 않았다. (뒤에서 자세한 설명이 나온다.)
학습 정보
- 우울증 데이터는 1(positive), 비우울증 데이터는 0(negative)으로 레이블을 매겼다.
- DCB의 특징(feature) 차원은 2차원 이미지에 대해 256, 256, 128, 64, 64로, 얼굴 방향에 대해 128, 64, 256, 128, 64로 사용했다.
- optimizer는 SGD, 학습률은 2e-5, momentum은 0.9이다.
- mini-batch 크기는 8이다.
다른 모델과의 비교
(표의 일부 내용은 생략했다. 원본은 논문을 참고하자.)
선행 연구와 비교
| Method | Feature | Accuracy | F1-score |
|---|---|---|---|
| SVM | V | - | 0.500 |
| CNN | AUs+Gaze+Pose | - | 0.530 |
| SGD-SVM | 3D Landmarks+Gaze+Pose | - | 0.63 |
| C-CNN | A+L+3D Landmarks | - | 0.769 |
| SS-LSTM-MIL | 2D Landmarks | - | 0.783 |
| 본 연구 | 2D Landmakrs+Pose | 0.857 | 0.800 |
A는 오디오, V는 시각 정보, L은 텍스트 정보를 뜻한다. 본 연구는 다른 single-modal과 multi-modal 모델에 비해 높은 점수를 보였다. 이를 통해 본 연구의 모델이 시각 정보를 종합적으로 잘 판단했다고 평가할 수 있다.
Single Modal과 비교
초기에는 하나의 특징만으로 이용해, 하나의 TDCN branch로 학습했다.
| Feature | Accuracy | Recall | F1-score |
|---|---|---|---|
| AUs | 0.638 | 0.357 | 0.370 |
| Gaze | 0.596 | 0.214 | 0.240 |
| Pose | 0.660 | 0.214 | 0.273 |
| 2D Landmarks | 0.596 | 0.214 | 0.240 |
| Now | 0.660 | 0.643 | 0.530 |
두 종류의 특징을 결합할 때 가장 높은 점수를 기록했다. Recall이 크게 향상된 것을 통해 우울증 환자를 더 잘 찾아낸 것을 알 수 있다. 이는 ADD 문제를 효과적으로 해결한다는 사실을 입증한다.
Multi Modal과 비교
| Features | Accuracy | F1-Score |
|---|---|---|
| Pose+AUs | 0.800 | 0.720 |
| Landmarks+AUs | 0.829 | 0.786 |
| Landmarks+Pose | 0.857 | 0.815 |
| Landmarks+Pose+Gaze | 0.743 | 0.609 |
| Landmarks+AUs+Pose+Gaze | 0.686 | 0.421 |
다른 특징으로 학습한 결과 2D Landmark + Pose가 가장 높은 성능을 기록했다. 단일 모델보다 여러 특징을 조합한 멀티 모달의 성능이 전반적으로 더 우수했다. 여러 조합을 시도한 결과 랜드마크를 사용했을 때 대체적으로 좋은 성능을 보였다. 랜드마크가 얼굴 특징에 대한 정교한 정보를 제공하기 때문으로 분석된다. 3개 이상의 특징을 결합할 경우 분명한 성능 감소가 나타났다. 특징이 많아지면 모델의 크기가 커지며 over-fitting 문제가 발생하기 때문으로 보인다.
데이터 전처리에 따른 비교
| Method | Accuracy | F1-score |
|---|---|---|
| Head-first | 0.857 | 0.815 |
| Average | 0.629 | 0.519 |
데이터 전처리 방법에 따라서 성능 차이가 있었다. Head-first는 본 연구에서 사용한 방식으로 데이터 처음부터 5000씩 잘라 사용한 방법이다. Average는 데이터를 여러 조각으로 나눈 뒤 soft predicting 점수의 평균을 이용해 선택하는 방식이다. 표에서 볼 수 있듯이 Head-first 방식이 가장 좋은 성능을 보였다. 분할된 데이터 조각(sub-sequences)은 우울증 특징을 담고 있지 않을 수 있기 때문에 average 방식이 낮은 점수를 기록했다고 볼 수 있다.
일부 모듈 제거
| backbone | Accuracy | F1-score |
|---|---|---|
| TCN | 0.686 | 0.522 |
| TDCN | 0.857 | 0.815 |
TDCN 대신 TCN을 사용할 경우 성능 저하가 발생했다. 뿐만 아니라 낮은 FLOPs(FLoating point Operations Per Second)를 보여 TDCN의 연산 효율이 좋다는 점도 알 수 있었다.
(결과 표 생략)
FWA를 제거한 모델, Max-Pooling 대신 Average-Pooling을 사용한 모델을 학습해봤지만 성능 향상은 없었다.
구현 계획
논문에서 제안한 TDCN을 단순화한 모델을 목표로 했다.
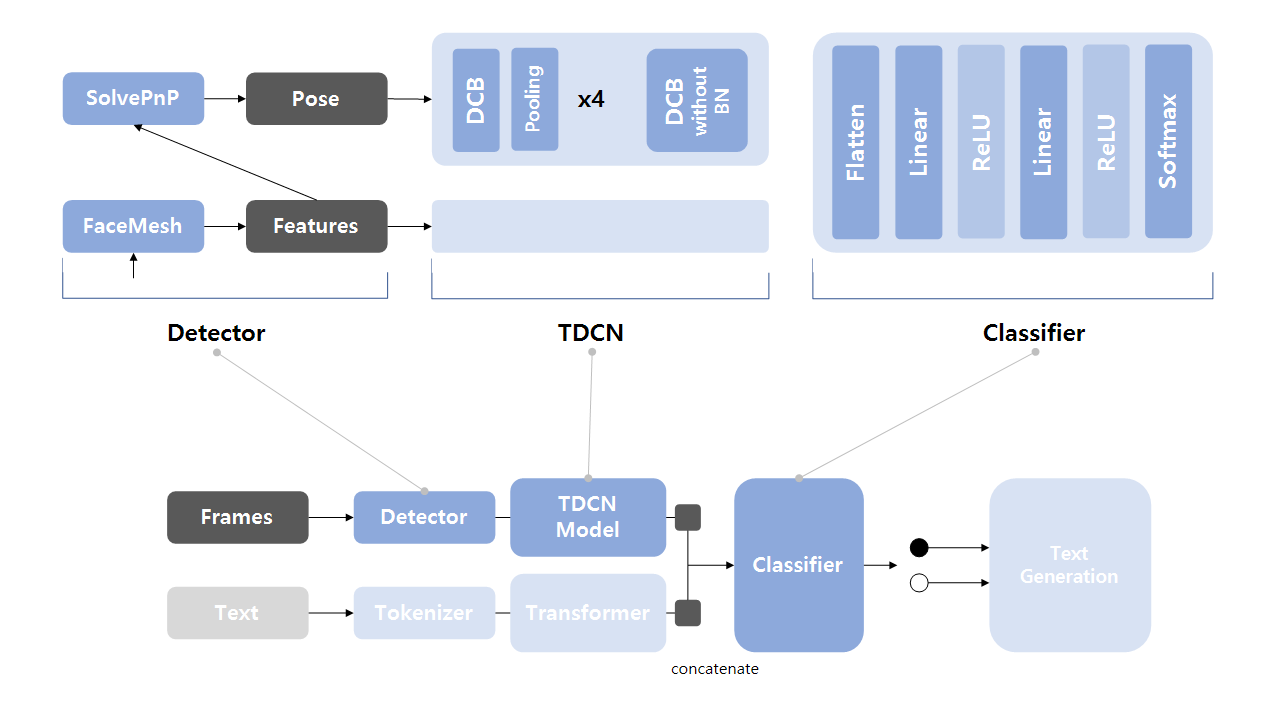
변경된 내용
- FWA 대신 Classifier 층 사용
- DCB 내 Dilation이 2인 DCN과 1CNN만 사용
Github 코드: archive/tdcn_demo.ipynb
- batch size: 8
- learning rate: 1e-5
- optimizer: Adam
- loss function: CrossEntropy
모델 구조에서 Detector는 얼굴 랜드마크 정보를 추출하는 모듈로 Github: archive에서 확인할 수 있다.
학습 결과 분석
Accuracy는 0.702, F1-score는 0.000이다. 결과값을 살펴보면 레이블과 관계없이 모든 데이터에 대해 [1.000 0.000]을 뱉어낸다. 비우울증(0) 데이터가 훨씬 많기 때문에 이런 편향된 결과를 도출했다고 생각한다.
박사과정의 연구원분께 조원을 구하니 간단한 CNN 기반의 Base 모델을 만들어 학습하라고 말해주셨다. 만약 Base 모델에서 유의미한 학습이 진행되면 우리의 모델이 잘못 설계되었다고 생각할 수 있다. 반면, Base 모델에서도 같은 현상이 일어난다면 데이터 전처리에 문제가 있을 가능성이 높다. CNN 기반의 Base model에서도 유사한 현상이 발견됐고 데이터에 문제가 있는 것으로 판단했다.
프로젝트 마무리하며
여러 팀원분의 도움을 받아 문제를 해결하려 했지만 결국 답을 찾지 못했다. 2월에 군입대가 예정되어 있었기 때문에 나는 프로젝트를 그만둘 수 밖에 없었다. 답을 찾지 못하고 마무리하니 찝찝했다. 그래도 논문 하나를 깊게 분석하고, 논문 저자와 컨택하며 문제를 해결하려는 시도는 값진 경험이라고 생각한다. 또 NIPA나 CLOVA 같이 외부 서버에 접속해 학습하는 기회도 얻을 수 있었다. 비록 분명한 결과물은 없지만 탐구하고 고민하는 과정에서 그 어느 때보다 많이 배울 수 있는 프로젝트였다.