실시간 얼굴 인식 모델 (HOG, FaceMesh)
실시간 얼굴 인식을 활용한 프로젝트를 진행할 당시, 여러 얼굴 인식 모델을 찾고 테스트했다. 영상 정보를 실시간으로 처리해야 했기 때문에 빠르고 정확한 모델이 필요했다. 여러 모델이 있지만 준수한 성능을 보였던 두 모델에 대해 적어보았다.
이 글에서 ‘모델이 성능이 준수하다’의 기준은 ‘실시간으로 얼굴을 인식하고 처리할 수 있는가’이다. 예를 들어, dlib의 CNN을 기반으로한 모델의 경우 이미지 처리 성능은 좋지만 실시간 영상 처리에서는 무거운 모델이다.
Opencv
우선 이미지와 영상을 다루기 위해서는 opencv를 이해해야 한다. Python과 C++이 있지만 이 글은 Python만 다룬다.
색상 이미지
1
2
3
4
import cv2
img = cv2.imread("face.png")
img.shape # (201, 223, 3) -> (가로, 세로, 채널)
imread로 이미지를 읽어오면 3차원 정보를 가지고 있다. 컬러 이미지가 순서대로 B(blue), G(green), R(red) 3가지 정보를 가지고 있기 때문이다.
1
2
3
4
5
6
7
8
img = cv2.imread("dog.jpeg")
img[:,:,1] = 0 # Green
img[:,:,2] = 0 # Red
cv2.imshow(img) # Blue only
# 아무 입력이나 대기
cv2.waitKey(0)
cv2.destroyAllWindows()
특정 채널을 0으로 처리하면 색상이 변하는 것을 볼 수 있다.
imshow는 이미지가 보여진 다음 바로 종료되기 때문에 waitKey를 통해 꺼지지 않고 대기하도록 한다. (이후 코드에서는 생략하겠다.)
만약 Jupyter-notebook에서 imshow를 한다면 plt.imshow()를 이용하거나, Colab의 경우 cv2_imshow를 제공한다.
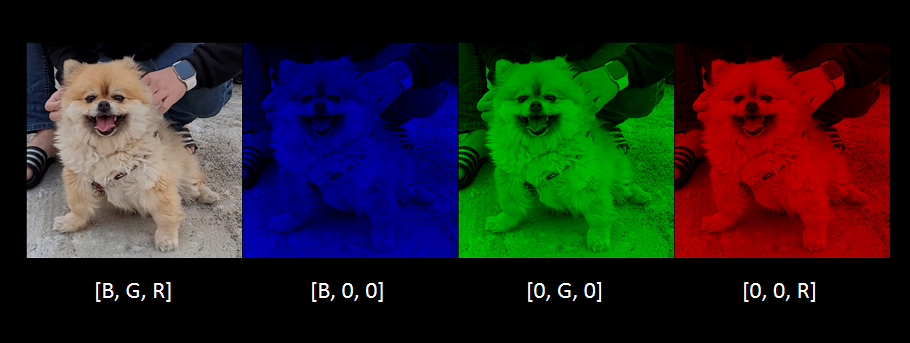 각각 BGR 채널의 모습이다.
각각 BGR 채널의 모습이다.
흑백 이미지
1
2
3
4
img = cv2.imread("dog.jpeg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img.shape
# (669, 669) -> (가로, 세로)

직접 채널을 조작할 수도 있지만 cvtColor를 통해 간단하게 처리할 수 있다. 보다시피 흑백 이미지는 1개의 채널만 가진다.
영상
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import cv2
cap = cv2.VideoCapture("penguin.gif")
# cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if ret:
# 정상적으로 frame을 읽어왔을 때
cv2.imshow(frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
# 키보드에서 'q'를 입력하면 종료
break
else:
# 정보를 읽지 못 했을 때
pass
cap.release()
cv로 영상을 읽는 방법이다. VideoCapture의 파라미터는 영상 경로 또는 사용할 카메라의 인덱스이다.
0: 카메라 자동 선택int: 사용할 카메라 인덱스str: 불러올 영상 파일 주소
그리고 VideoCapture.isOpened일 동안 계속해서 정보를 읽어온다. 마지막에 release로 닫는다.
영상은 수많은 이미지가 연속적으로 재생되는 것이다.

남아프리카에 있을 때 찍은 펭귄이다. 이 영상도 이미지들이 연속으로 이어져 있는 구조다.
 위 영상을 분리한 결과
위 영상을 분리한 결과
따라서, 영상 처리는 이미지 처리와 동일하다. 이때 영상의 각 이미지를 frame이라고 한다.
Dlib
1
2
3
4
import dlib
detector = dlib.get_frontal_face_detector()
faces = detector("face.png")
dlib의 get_frontal_face_detector는 HOG(Histogram of Oriented Gradient)+SVM을 활용해 사람 얼굴을 인식한다. 위와 같이 함수를 이용해 detector 객체를 가져오고, 사람 얼굴 이미지를 입력하면 관련 정보를 반환한다.
HOG
HOG는 이미지의 Gradient 정보를 이용해 특정 사물/ 인물의 윤곽을 찾아내는 알고리즘이다.
 경계선과 물체의 색(밝기)이 다르다.
경계선과 물체의 색(밝기)이 다르다.
우리는 사물의 경계를 인식할 때 밝기 또는 특정 색상 값의 차이를 이용한다. 위 그림의 경우, 코알라와 배경의 색상이 뚜렷하게 차이난다. 따라서 코알라가 어디있는지 알 수 있다. 이 원리를 이용하면 사람/ 사물의 경계를 찾을 수 있다.
Image Gradient
색상 이미지는 pixel 단위로 구성되어 있고, 각 pixel은 0~255 사이의 값을 가진다. 이때 인접한 pixel과의 차이가 Gradient이다.
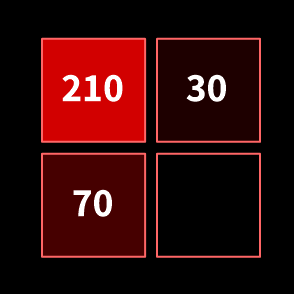
210 값을 가진 pixel을 기준으로 계산해보자.
M는 Gradient의 크기, θ는 Gradient의 방향이다.
Histogram
픽셀 간의 차이를 크기(M)와 방향(θ) 두가지 측면에서 계산했다. 이미지를 8x8 단위로 분할하면 cell이 된다. 각 cell은 histogram을 만든다.
Gradient 방향을 기준으로 해당하는 bin(histogram의 범위)을 찾는다. 그리고 해당 픽셀의 크기를 히스토그램에 더한다.
4x4로 예시를 들면 아래와 같다.
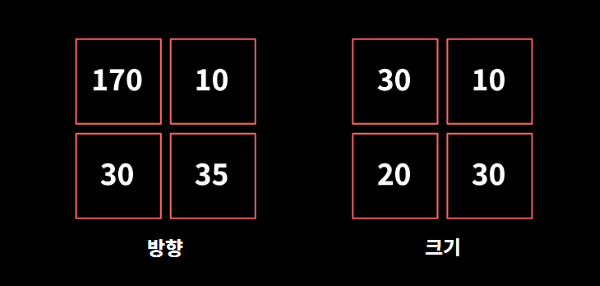
첫 셀의 방향은 170이다. 따라서 160~180 구간에 해당한다. 이 셀은 30의 크기를 가지므로 160~180 구간에 30을 더한다. …
1
2
3
4
5
6
7
8
방향: 크기의 합
--------------------
0~ 20: 10
20~ 40: 20 + 30
40~ 60: 0
...
160~180: 30
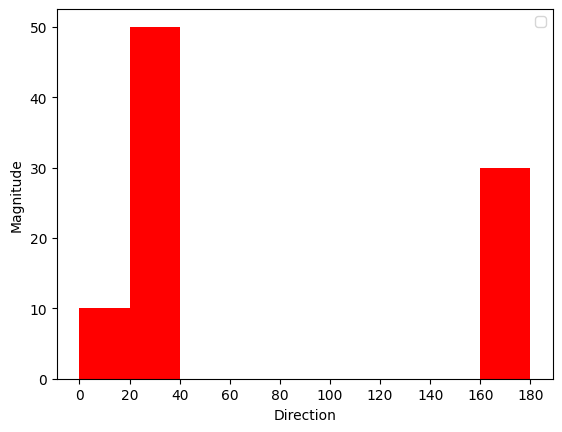
계산된 히스토그램은 “어느 방향”으로 “얼마나 큰” 차이가 있는지 나타낸다.
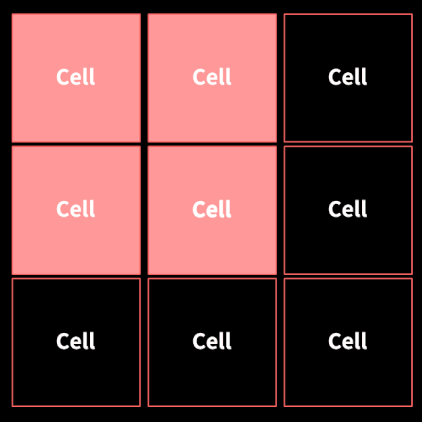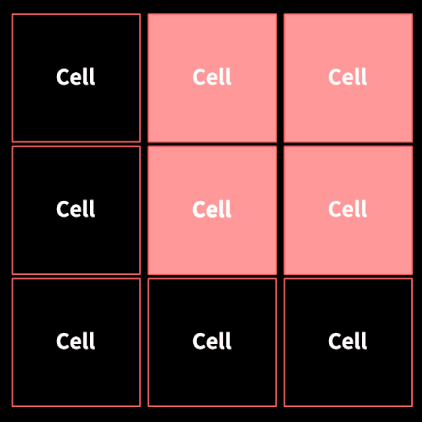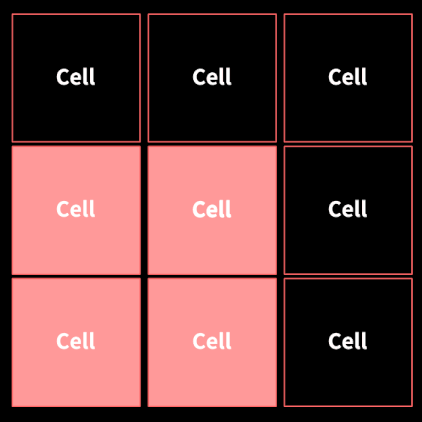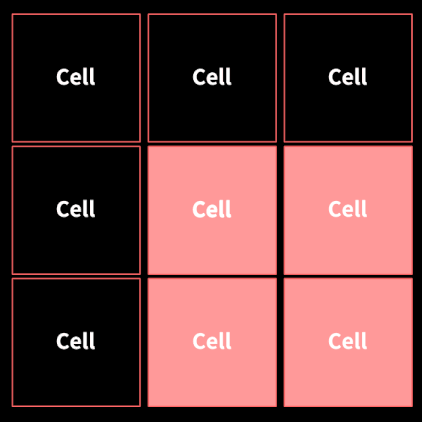
셀(8x8) 단위로 만든 히스토그램을 16x16 단위의 block으로 합친다. 이후 정규화를 통해 일반적인 특성으로 변환시켜준다.
SVM
HOG로 만들어진 히스토그램 값은 SVM(Support Vector Machine)으로 분류된다. SVM은 Support Vector를 기준으로 Margin을 최대화하는 머신러닝 분류 기법으로 대체적으로 준수한 성능을 보인다.
SVM에 대한 정보는 “Support Vector Machine”글을 참고하자.
실행
흑백 이미지를 이용해도 얼굴을 찾을 수 있다. 흑백 이미지(밝기)는 컬러 이미지(RGB 색상)와 달리 채널을 하나만 가지기 때문에 연산량을 줄일 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import cv2
import dlib
# 이미지를 불러와 흑백으로 변경
img = cv2.imread("face.png")
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 얼굴 인식
detector = dlib.get_frontal_face_detector()
faces = detector(gray)
for face in faces:
# 위치 정보 가져오기
left = face.left()
right = face.right()
top = face.top()
bottom = face.bottom()
# 위치 정보를 활용해 사각형 그리기
img = cv2.rectangle(
img, (left, top), (right, bottom), (0, 0, 255), 3
)
cv2.imwrite("face-rect.jpg", img)
cv2.imshow(img)


위 사진에서 보는 것과 같이 인식된 얼굴의 top, bottom, left, right 좌표를 가져올 수 있다.
이를 응용하면 얼굴 블러 처리도 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import cv2
import dlib
img = cv2.imread("face.png")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
detector = dlib.get_frontal_face_detector()
faces = detector(gray)
for face in faces:
left = face.left()
right = face.right()
top = face.top()
bottom = face.bottom()
blurred = cv2.blur(img[top:bottom, left:right], (30, 30))
img[top:bottom, left:right] = blurred
cv2.imshow(img)

얼굴이 인식되면 얼굴을 blur한 후 화면에 보여주는 예시이다.
HOG 장단점
해당 detector는 CPU 환경에서도 잘 작동한다는 장점이 있다. 가볍고 속도는 빠르지만 인식률이 조금 아쉽다.
frontal_face_detector라는 이름처럼 정면을 보지 않는 얼굴에 대한 인식 성능이 상대적으로 떨어진다. 그리고 얼굴이 작거나 이미지(카메라) 해상도가 낮은 경우 잘 인식하지 못한다.
FaceMesh
mediapipe에서 제공하는 FaceMesh는 얼굴 랜드마크를 검출한다.
관련 정보는 해당 논문에서 확인할 수 있다.
“Real-time Facial Surface Geometry from Monocular Video on Mobile GPUs”
모델에 대해 “straightforward residual neural network architecture”라고만 표현하고 있다…
Install
1
2
$ pip install mediapipe
$ pip install protobuf==3.20.*
pip를 통해 mediapipe를 설치한 후, protobuf를 다운그레이드 해줘야 한다.
랜드마크 그리기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import cv2
import mediapipe as mp
# 얼굴 검출을 위한 객체
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(
refine_landmarks=True,
static_image_mode=True,
max_num_faces=3,
)
# Face Mesh를 그리기 위한 객체
mp_drawing = mp.solutions.drawing_utils
drawing_spec = mp_drawing.DrawingSpec(thickness=1, circle_radius=2)
# 이미지 읽기
image = cv2.imread("face.jpg")
# 얼굴 검출
results = face_mesh.process(image)
# Face Mesh 그리기
if results.multi_face_landmarks:
for single_face_landmarks in results.multi_face_landmarks:
mp_drawing.draw_landmarks(
image=image,
landmark_list=single_face_landmarks,
connections=mp_face_mesh.FACEMESH_CONTOURS,
landmark_drawing_spec=drawing_spec,
connection_drawing_spec=drawing_spec,
)
cv2.imshow(image)
mp.solutions.face_mesh.FaceMesh는 얼굴의 랜드마크 검출을 위한 객체이다.
refine_landmarks: True일 때, 눈과 입술 주변 랜드마크를 정교하게 검출한다.static_image_mode: True일 경우, 모든 프레임에 대해 얼굴 검출을 진행한다. False일 경우, 얼굴을 추적(tracking)해 랜드마크를 검출한다. (모든 프레임에 대해 얼굴 검출을 진행하지 않고, 첫 프레임에서 얼굴을 검출한 후 이후 프레임은 tracking 방식으로 랜드마크를 추출한다. 만약 tracking을 통해 얼굴 검출이 되지 않을 경우 다시 얼굴 검출을 진행한다.)max_num_faces: 최대로 검출할 얼굴의 개수를 설정한다.
FaceMesh configurations_options에서 다른 파라미터 정보를 확인할 수 있다.
process를 통해 객체 검출을 진행하고, multi_face_landmarks를 통해 그 정보를 확인할 수 있다.
mp.solutions.face_mesh.DrawingSpec은 랜드마크 출력을 위한 객체다. draw_landmarks를 이용하면 이미지에 Face Mesh가 출력된다. 아래 사진을 참고하자.
FaceMesh 장단점
심심할까봐 식상한 사진말고 날 것을 가지고 와봤다.

사람이 많아도, 모자를 써도, 선글라스를 써도 잘 찾아내는 모습이다. (물론 이미지를 처리할 때는 모자이크 안 된 원본을 썼다.)
Face Mesh는 모바일 GPU 환경/ CPU 환경에서 잘 작동하도록 제작되었기 때문에 고성능 컴퓨팅 자원을 요구하지 않는다. 또 한 대의 카메라만으로도 잘 동작한다는 장점이 있다. 만약 디바이스에 GPU가 있다면 알아서 GPU 자원을 잘 사용한다. 데이터를 학습하며 여러 조명(lighting) 환경에서 촬영된 데이터를 사용했기 때문에 빛의 영향을 적게 받는다.
기존 방식은 영상의 모든 프레임에서 detector를 거쳐 얼굴을 검출하는 반면, Face Mesh는 (트래킹 모드에서) 이전 프레임 정보를 활용해 얼굴을 검출한다. 그리고 얼굴을 인식하기 힘든 특별한 상황이 발생했을 때 detector를 거쳐 얼굴을 재검출한다. 이 기능은 성능에 큰 이점을 준다. 정말 좋은 아이디어라고 생각한다.
하지만 마스크를 쓰거나 얼굴 일부가 잘린 이미지는 인식하지 못했다.
랜드마크 좌표
FaceMesh는 468개의 랜드마크를 제공한다. 랜드마크 인덱스 정보는 Github:face_geometry에서 확인할 수 있다. 링크 잘못된 거 아니다. [새 탭에서 이미지 열기]하고 확대하면 숫자가 적혀있다.
{kind=link}
1
2
3
for single_face_landmarks in results.multi_face_landmarks:
coordinates = single_face_landmarks.landmark[랜드마크 인덱스]
coordinates.x, coordinates.y, coordinates.z
landmark에서 원하는 인덱스를 통해 좌표를 가져오고 x, y, z를 통해 값을 가져온다.
x와y는 정규화된 값으로 0 ~ 1사이의 값을 가진다.z는 Mesh 중앙을 지나는 평면을 기준으로 상대적인 깊이를 나타낸다.
예시: 코끝 랜드마크
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import cv2
import mediapipe as mp
# 코끝 인덱스 번호
NOSE_INDEX = 1
mp_face_mesh = mp.solutions.face_mesh
face_mesh = mp_face_mesh.FaceMesh(
static_image_mode=False,
max_num_faces=1,
)
# 카메라 실행
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if ret:
frame = cv2.flip(frame, 1)
image_height, image_width, _ = frame.shape
# 얼굴 검출
results = face_mesh.process(frame)
if results.multi_face_landmarks:
for single_face_landmarks in results.multi_face_landmarks:
# 코끝의 좌표값 구하기
coordinates = single_face_landmarks.landmark[NOSE_INDEX]
x = coordinates.x * image_width
y = coordinates.y * image_height
z = coordinates.z
# x, y 좌표 화면에 그리기
cv2.circle(frame, (int(x), int(y)), 5, (255, 0, 0), -1)
cv2.imshow("Frame", frame)
if cv2.waitKey(3) & 0xFF == ord("q"):
break
else:
break
cv2.destroyAllWindows()
cap.release()
카메라가 연결된 PC에서 실행해보면 코끝에 점이 찍히는 모습을 볼 수 있다. 참고로 코끝 인덱스는 1이다.
이 글의 모든 사진은 필자가 직접 촬영한 사진이므로 무단 복제/ 공유는 자제해주길 바랍니다.