Python 비동기/병렬 처리는 효율적일까?
Python으로 프로젝트를 진행하던 중, Python을 비동기로 처리하면 빠를까?에 대한 궁금증이 생겼다.
우리는 시간이 걸리지만, 우리 코드가 아닌 곳에서 시간이 걸리는 활동을 찾고 싶다. 데이터베이스를 조회할 때나 외부 서비스를 접근할 때, 사용자 입력을 기다릴 때 같이 우리 프로그램이 다른 작업이 끝나기를 기다려야 하는 상황 말이다. 이런 순간이 바로 CPU가 손가락만 빨면서 기다리는 대신 좀 더 생산적인 일을 할 수 있는 기회다. - 실용주의 프로그래머 (Program Programming Programmer)
그렇게 비동기 처리에 대한 조사와 실험이 시작되었다. 그리고 비동기를 찾던 중, 병렬 처리에 대한 내용도 알게 되었다.
비동기 처리의 종류
Sync/ Async
두 항목을 나누는 기준은 요청한 작업이 진행되는 순서이다.
Synchronous(동기): 요청된 작업이 순차적으로 진행된다.Asynchronous(비동기): 요청된 작업 순서가 보장되지 않는다.
예를 들어, 1, 2, 3번 작업을 순서대로 요청했다고 하자. 동기인 경우는 순서대로 1번, 2번, 3번 작업을 수행하고 결과를 반환한다. 반면 비동기 작업은 1번, 3번, 2번과 같이 다른 순서로 결과를 반환할 수 있다.
1
2
3
4
5
6
7
요청: 1 → 2 → 3
[ 결과 ]
- 동기: 1, 2, 3 (항상)
- 비동기: 1, 3, 2
2, 1, 3
(다양한 경우 가능)
Blocking/ Non-Blocking
두 항목을 나누는 기준은 함수의 제어권에 있다.
Blocking: 함수가 호출되어 제어권을 받은 후 다시 넘겨주지 않는다.Non-Blocking: 함수가 호출되어 제어권을 받은 후 즉시 넘겨준다.
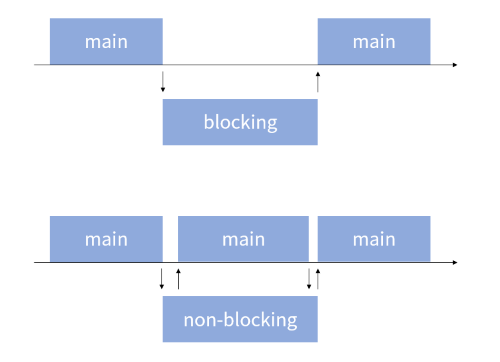
쉽게 생각해서 자신이 실행되는 동안 다른 함수가 실행되도록 허락하지 않는 상태가 blocking이다. 반면 non-blocking은 호출된 후 제어권을 다시 main 측으로 넘겨준다. 따라서 main 측에서는 다른 작업을 수행할 수 있게 된다.
Asynchronous Non-blocking
그렇다면 효율적으로 비동기를 실행하기 위해서는 Asynchronous+Non-blocking으로 실행되어야 한다는 것을 알 수 있다. 크롤링을 수행하는 상황을 가정해 보았다.
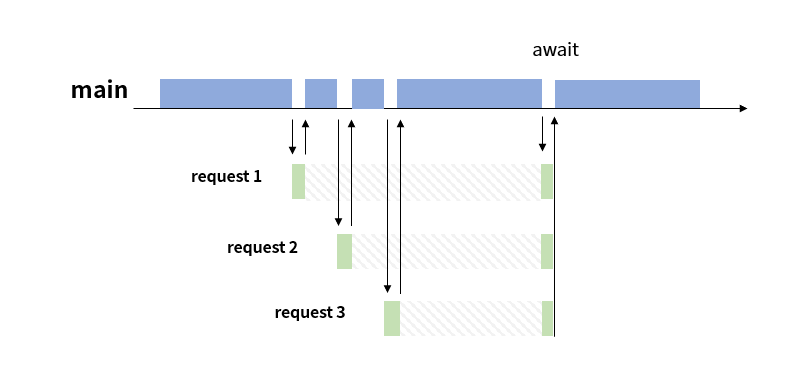
request가 먼저 실행되었다고 해서 결과를 먼저 반환하지 않는다. 따라서 async(비동기)라고 할 수 있다. 또한 main 측에서 제어권을 받아 요청 1을 실행한 후 다른 요청을 보낼 수 있도록 main 측에 제어권을 반납한다. main 측은 요청 2를 실행하고, 위 과정을 계속 반복한다. 제어권을 즉시 주고받으며 main 측에서 다른 작업을 수행할 수 있도록 하는 것으로 보아 request 과정은 non-blocking이다.
만약 별도의 장치 없이 Python을 이용해 request 작업을 수행하면 Synchronous + Blocking 방식으로 작업하게 된다.
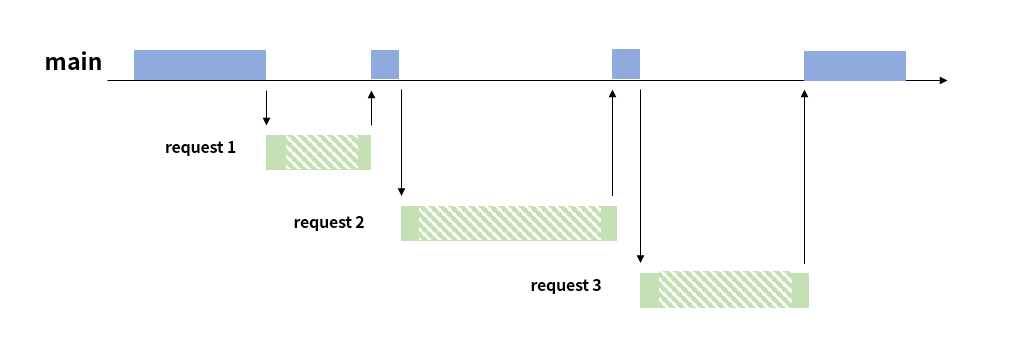
이 방식은 request를 실행하고 결과 값을 받기까지 대기 시간이 발생한다. 하지만 blocking 상태이기 때문에 main 측에서도 별다른 작업을 하지 못하고 무작정 기다려야 한다. 이 과정에서 시간이 낭비되는 것이다.
이러한 원리는 I/O 작업에도 동일하게 적용된다. 따라서 Async+Non-blocking을 이용해 I/O 작업을 수행하면 효율적으로 처리할 수 있다. (AIO)
Sync/ Async 처리와 Blocking/ Non-Blocking에 대한 설명을 찾아보면 “Boost application performance using asynchronous I/O”에 작성된 이미지가 가장 많이 보인다. 4가지 상황에 대한 예시가 그림으로 잘 정리되어 있어 한 번 읽어보는 것을 추천한다.
Python의 비동기 처리
그래서 Python으로 비동기 처리를 할 수 있는가?가 의문이었다.
asyncio
Python은 asyncio를 활용해 비동기 처리를 지원한다.
1
import asyncio
asyncio의 경우, 파이썬 버전에 따라 많은 변화가 있었다. 아래 글에 포함된 코드는 Python 3.9를 활용해 코드를 실행해 보았다. 특히 3.7 이전의 버전을 활용한다면 아래 글의 예제 코드가 실행되지 않을 수 있다.
아래 함수를 실행해보면 동시에 비동기로 실행되는 것을 볼 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import asyncio
import time
async def f(t):
""" 실행에 약 t초가 소요되는 함수 """
await asyncio.sleep(t)
async def main():
task1 = asyncio.create_task(f(6))
task2 = asyncio.create_task(f(7))
await task1
await task2
start = time.time()
ret = asyncio.run(main())
end = time.time()
print(f"시간: {round(end - start)}초")
# 시간: 7초
동기로 실행되었다면 6초가 걸리는 함수와 7초가 걸리는 함수가 순서대로 실행되어 약 13초가 소요되었을 것이다. 하지만 위 코드는 약 7초가 소요되었다. 이를 통해 우리가 의도한 대로 실행된다는 것을 알 수 있다.
asyncio.sleep는 time.sleep과 같은 역할을 하는 non-blocking 함수이다. time.sleep은 blocking 함수이기 때문에 time.sleep을 활용해 실행해보면 약 13초가 소요된다.
실제 구현
Python의 함수는 기본적으로 Blocking 상태이다. 함수가 실행되는 동안 main 함수는 아무것도 하지 못하고 반환 값을 기다려야만 한다. 하지만 event loop에 run_in_executor를 활용하면 Non-blocking으로 동작할 수 있다.
1
2
# loop = asyncio.get_event_loop()
loop.run_in_executor(None, 함수, 인자1, 인자2 ... )
예시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import asyncio
import time
import requests
urls = ["https://www. ... ", ... ] # 10개의 url 주소
headers = { "User-Agent": "Mozilla/5.0 ... "}
async def get_reqeust(url):
request = await loop.run_in_executor(None, requests.get, url, headers)
return request.status_code
async def main():
tasks = [asyncio.create_task(get_reqeust(url)) for url in urls]
ret = await asyncio.gather(*tasks)
return ret
start = time.time()
loop = asyncio.get_event_loop()
status = loop.run_until_complete(main())
loop.close()
end = time.time()
print(f"시간: {round(end - start)}초, 실행 결과: {status}")
1
시간: 1초, 실행 결과: [200, 200, 200, 200, 200, 200, 200, 200, 200, 200]
10개의 URL에 접속해 모두 정상적(200)으로 정보를 가져왔으며 총 1초가 소요되었다.
같은 작업을 동기 방식으로 진행해 보았다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 생략
def get_reqeust(url):
request = requests.get(url, headers)
return request.status_code
def main():
ret = [get_reqeust(url) for url in urls]
return ret
start = time.time()
status = main()
end = time.time()
print(f"시간: {round(end - start)}초, 실행 결과: {status}")
1
시간: 7초, 실행 결과: [200, 200, 200, 200, 200, 200, 200, 200, 200, 200]
같은 URL에 접속해 정보를 가져왔지만 시간이 7배 정도 더 오래 걸렸다. 접속해야 하는 URL의 수가 많을수록 차이는 더 심해질 것이다.
위 결과를 정리해보면 아래 표와 같다.
| 동기 | 비동기 | |
|---|---|---|
| 접속한 URL | URL 10개 | URL 10개 |
| 소요 시간 | 약 7초 | 약 1초 |
Python 비동기 장점
Request, I/O bound 프로세스와 같이 딜레이가 발생하는 작업에서 뛰어난 효과를 보인다. 쉽게 말해 서버에 정보를 요청하거나 데이터를 읽는 등 작업에 유리하다는 의미이다. 대기 시간이 발생하는데 상황에서 이러한 시간을 다른 작업을 수행하는데 활용함으로써 전체적인 소요 시간이 감소하는 것이다.
Python 비동기 단점
하지만 CPU bound 작업은 다르다. 파이썬의 비동기는 병렬적(parallel)으로 처리되는 것이 아니라 동시(concurrent)에 처리되는 것이다. 반복적인 연산을 수행하는 코드를 실행해보면 오히려 비동기로 처리했을 때 더 많은 시간이 소요되었다. 일반 이터레이터(동기 방식)를 사용했을 때 21초가 소요되는 작업을 비동기 이터레이터는 29초가 소요되었다.
CPU Bound
이 부분부터는 이론적인 내용을 중심으로 작성하였다. 현재 로컬에서 멀티 코어 CPU를 사용해 정확히 측정할 수 있는 환경이 안 된다.
multi-thread도 느리다
CPU 작업에서 비동기 처리는 동기 처리보다 느린 모습을 보였다. 그렇다면 multithread를 이용해 처리하면 빠를까? 결론부터 말하면 그건 또 아니다.
이해를 위해 먼저 GIL을 알아야 한다.
GIL
GIL(Global Interpreter Lock)은 한 프로세스 내에서 하나의 쓰레드만 인터프리터에 접근할 수 있도록 하는 뮤텍스(mutual exclusion)의 일종이다. GIL을 사용하는 이유는 경쟁 상태(race condition)의 위험 때문이다. Python에는 Garbage Collector(GC)가 존재한다. Python 객체가 몇 번 참조되는지 객체 참조(reference count)를 할 때 사용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import sys
class Obj:
pass
a = Obj() # a 참조: 1회
sys.getrefcount(a) # a 참조: 2회 (임시)
>>> 2
b = a # a 참조: 2회
sys.getrefcount(a) # a 참조: 3회 (임시)
>>> 3
b = 0 # a 참조: 1회
sys.getrefcount(a) # a 참조: 2회 (임시)
>>> 2
(1) a가 생성된 후, (2) getrefcount에서 임시로 참조되며 총 2번의 참조가 발생한다. (3) b가 a를 참조하고 getrefcount에서 임시로 참조되며 총 3번의 참조가 일어난다. b에서 a에 대한 참조가 사라지면 다시 1로 바뀌게 된다. 이렇게 객체를 몇 번 참조했는지 세는 것을 reference count라고 한다. 이때, 참조가 0이 되면 파이썬에서 더 이상 객체를 참조하지 않기 때문에 GC에 의해 메모리에서 삭제된다. 만약 여러 스레드가 접근할 수 있도록 하면 예상치 못한 충돌이 발생할 가능성이 생긴다. 따라서, 락(Lock)을 걸어 하나의 스레드만 접근할 수 있도록 허용한다.
이러한 GIL의 특성 때문에 CPU 연산의 경우, 멀티 스레드를 활용하는 것보다 싱글 스레드를 사용하는 것이 오히려 효율적이다. 병렬적인 처리가 안 되고 context switching만 실행하기 때문에, 오히려 시간이 더 많이 드는 경우가 생긴다.
multi-process로 해결
GIL은 하나의 프로세스 당 하나의 쓰레드만 접근하도록 한다. 그렇다면 여러 개의 프로세서를 생성하면 어떨까? 이 경우는 성능 향상이 보인다. Python은 multiprocessing을 통해 멀티 프로세싱을 지원한다.
정리
Async+Non-blocking작업을 통해 대기 중인 자원을 효율적으로 사용할 수 있다.asyncio: request 작업에서 성능 향상을 기대할 수 있다.multithread: I/O 작업에서는 성능 향상을 기대할 수 있지만,GIL로 인해 병렬 처리에 제한이 있다.multiprocessing: CPU bound에서 병렬 처리로 성능 향상을 기대할 수 있다.
Lei Mao님의 글을 보면 아주 적절한 비유가 있다.
| 개념 | 비유 |
|---|---|
| asyncio | 한 주방에서 요리사 한 명이 10개의 요리를 한다. |
| multithread | 한 주방에서 요리사 10명이 10개의 요리를 한다. |
| multiprocessiong | 10개의 주방에서 요리사 10명이 10개의 요리를 한다. |
호기심에 시작한 삽질치고는 너무 거창해졌다. 직접 테스트를 할 수 없는 환경이라 확실한 결과는 못 찾았다. 하지만 CPU에 대해 더 자세히 찾아보고 공부할 수 있었다. 역시 깊게 팔수록 어려운 게 Python인 거 같다.
+ 2023.10
며칠전에 릴리즈된 Python 3.12을 보면, Per-Interpreter GIL을 도입했고 asyncio에서 75%의 속도 향상이 있다고 공개했다. 이로 인한 변화가 있는지도 문뜩 궁금하다.