웹 접근성 향상을 위한 FaceMouse 개발기
- v1.1: 2025-05
- Github & 데모 영상: denev6/face-mouse-control
- v1.0: 2022-07
모두가 마우스를 사용할 수 있을까요?
저희 외할아버지는 사고로 양손을 잃으셨어요. 이렇게 손이 불편한 분들은 마우스와 키보드를 어떻게 사용까요? 기업들은 각자의 방법을 통해 문제를 해결하려 했어요.
- Smyle Mouse는 일반 웹캠을 사용하여 PC를 제어할 수 있으며, 미소를 지어 마우스와 클릭을 제어하도록 설계됐어요. 소프트웨어를 사용하기 위해 한 달에 약 29$의 비용이 들어요.
- Kai는 사용자의 손에 착용하여 손과 손가락 움직임을 추적해 컴퓨터와 IoT 지원 장치를 제어해요. 그러나 이 접근 방식은 여전히 수동 제스처에 의존하기 때문에 손 사용에 불편함을 느끼는 사용자에게는 부적합해요.
- Leap Motion은 적외선 센서와 그 반사 신호를 사용해 손 제스처를 감지해요. 모니터 앞에 위치하여 사용자가 손 움직임을 통해 장치를 제어할 수 있도록 해요. Kai와 마찬가지로 손을 이용한 상호작용을 피하고 싶은 개인에게는 적합하지 않아요.
- Microsoft의 Windows 10 Eye Control은 Smyle Mouse와 유사한 기능을 제공하지만 추가 하드웨어가 필요해요. 구체적으로, Tobii Eye Tracker에서만 작동하며 표준 웹캠으로는 기능할 수 없어요. 이 시스템은 시선을 기반으로 마우스 커서를 제어하고 상호작용을 위해 사용자 지정 UI를 오버레이해요. 예를 들어, 사용자는 “클릭” 버튼을 응시하고 커서를 올린 다음, 클릭을 유발하기 위해 일정 시간 동안 초점을 유지해야 해요.
- LipStick Mouse는 미세한 입술 제스처를 사용해 전체 마우스 제어를 가능하게 해요. 정전식 센서는 클릭, 더블 클릭, 드래그, 스크롤을 포함한 다양한 기능을 지원하며, 감도와 매핑을 사용자 정의할 수 있어요.
상지 장애 사용자를 대상으로 한 여러 서비스가 있어요. 하지만 손을 사용하거나 별도의 하드웨어를 설치해야 해요. 그리고 단순한 조작을 넘어 실제 웹 사용 환경에서 겪는 문제를 고민하지 않았어요. 저희는 3가지 목표를 설정하고 소프트웨어를 기획했어요.
- 손을 이용하지 않고 마우스를 제어할 수 있어야 해요.
- 별도의 하드웨어 없이, 저성능 컴퓨팅 환경에서 사용할 수 있어여 해요.
- 웹 서비스를 불편함 없이 사용할 수 있어야 해요.
설계와 구현
손 대신 머리와 눈을 활용하자
마우스를 손으로 사용할 수 없다면 다른 신체 부위를 사용해야 해요. 동시에 학습 비용이 높지 않은, 직관적인 사용법이였으면 해요. 그래서 우리가 노트북을 사용하기 위해 앉아있는 모습을 상상해 봤어요. 눈 앞에 스크린이 있고, 위에 웹캠이 있죠. 웹캠은 사용자의 얼굴을 비추고 있어요. 이 상태에서 고개를 상하좌우로 움직이는 건 어떨까? 고개를 돌리는 동작은 큰 부담 없이 수행할 수 있으면서, 기존의 노트북 사용 방식을 그대로 적용할 수 있어요.

얼굴로 마우스 방향을 조절한다면, 클릭은 어떻게 구현할지가 문제에요. 사람의 얼굴에서 쉽게 제어할 수 있는 부분은 눈과 입이 있어요. Smyle는 웃는 표정을 지어 클릭을 구현했어요. 하지만 웃는 동작은 생각보다 얼굴 근육을 많이 사용해야 해요. 그에 비해 눈 깜빡임은 부담이 덜한 동작이죠. 따라서 저희는 눈 깜빡임을 클릭으로 정의했어요. 대신 자연스러운 깜빡임과 구분하기 위해 일정 시간 동안 길게 감아야 클릭으로 처리하도록 했어요.
최대한 가벼워야 한다
두번째로, 별도의 하드웨어 없이 일반 노트북에서 사용 가능해야 해요. 구체적으로 저전력 CPU 환경에서 GPU 없이 구동할 수 있어야 해요. 이 기준을 만족할 수 있는 얼굴 인식 모델과 눈 깜빡임 인식 알고리즘을 탐색했어요.
얼굴 랜드마크와 주시 방향

얼굴로 마우스를 제어하기 위해서 (1) 얼굴 랜드마크를 추출하고, (2) 얼굴이 바라보는 각도를 계산해야 해요. 얼굴 인식 알고리즘은 FaceMesh, HOG, SSD를 비교했어요. 구체적인 비교군은 다음과 같아요.
- 모델 1: FaceMesh로 랜드마크를 추출하고 solvePnP로 얼굴 각도를 출력.
- 모델 2: FaceMesh를 통해 랜드마크를 추출하고 2차원 알고리즘으로 각도를 출력.
- 모델 3: HOG + Linear SVM으로 감지된 얼굴 위치에서 Ensemble of Regression Trees를 통해 얼굴 랜드마크를 추출하고 2차원 알고리즘으로 각도를 출력.
- 모델 4: SSD로 감지된 얼굴 위치에서 Ensemble of Regression Trees를 통해 얼굴 랜드마크를 추출하고 2차원 알고리즘으로 각도를 출력.
- 모델 5: HOG + Linear SVM으로 얼굴 감지에 실패하면 SSD로 얼굴을 감지하고 Ensemble of Regression Trees를 통해 얼굴 랜드마크를 추출한 후 2차원 알고리즘으로 각도를 출력.
고개를 좌우로 돌리는 영상을 촬영하고 여러 평가 지표를 측정했어요. 실험은 저전력 CPU인 AMD Ryzen 5 3500 Matisse가 탑재된 노트북에서 실행했어요.
| 모델 | CPU 사용량 (%) | 메모리 사용량 (MiB) | 실행 시간 (s) | 성공률 (%) | 최대 각도 (°) |
|---|---|---|---|---|---|
| 1 | 12.4 | 32.93 | 1.12 | 100 | 좌: 37.7°, 우: 33.5° |
| 2 | 14.1 | 42.42 | 1.18 | 100 | 좌: 25.5°, 우: 28.3° |
| 3 | 19.9 | 19.40 | 13.62 | 84.8 | 좌: 14.7°, 우: 17.4° |
| 4 | 53.1 | 19.14 | 3.86 | 100 | 좌: 16.2°, 우: 12.3° |
| 5 | 36.5 | 31.18 | 12.87 | 100 | 좌: 16.2°, 우: 17.4° |
FaceMesh를 사용한 경우, 가장 빠른 실행 시간과 가장 낮은 CPU 사용률을 보였어요. HOG도 낮은 CPU 사용률을 보였지만 실행 시간이 13초로 가장 길 뿐만 아니라 성공률이 84.8%로 가장 낮았어요. SSD는 FaceMesh에 비해 4배가 넘는 CPU 사용률을 보였어요. 결과적으로 가볍고, 빠르고, 정확한 FaceMesh를 최종 모델로 채택했어요.
눈 깜빡임 판단
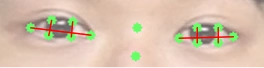
눈 깜빡임을 측정하기 위해서 EAR(Eye Aspect Ratio)를 사용했어요. 이전 단계에서 추출한 랜드마크 좌표를 활용해 눈의 가로 거리와 세로 거리의 비율을 계산해요. 눈의 세로 길이는 눈두덩과 눈 밑 사이 거리를 말해요. 눈 가로 길이 대비 세로 길이가 작아지면 눈을 감았다고 할 수 있어요. EAR을 채택한 이유는 연산 비용이 작기 때문이에요. 위에서 얼굴 랜드마크를 측정하며 많은 메모리 자원을 사용해요. 여기서 추가로 머신러닝 모델을 사용하면 더 정교한 측정이 가능할지라도, 실사용 성능은 떨어질 수 있어요. 따라서 추출된 랜드마크 정보를 최대한 활용할 수 있는 EAR을 선택했어요.
웹 서비스 사용에 불편함이 없을까
마우스가 필요한 상황이 여럿있지만, 특히 웹 서비스 사용에 집중했어요. 구글, 유튜브 등 일상적인 과제를 수행하는데 어려움이 없었으면 했어요. 선행 연구에 따르면, 웹 서비스는 작은 버튼이 많아 140% 정도 확대할 때 만족도가 높다고 해요. 그래서 사이드바를 통해 확대/축소 기능을 제공해요. 또한 마우스의 휠을 재현하기 위해 스크롤 버튼도 지원해요.
사용자 피드백
1차 테스트 결과
1차 MVP 테스트는 비장애인 6명을 대상으로 진행되었어요. 인터뷰 대상자는 웹 검색, 유튜브 시청 등 총 5개 과제를 수행하고, 8개 질문에 답했어요. 실험에서 얻은 피드백은 다음과 같아요.
- 프레임 드랍(frame drop) 문제를 발견했으며 마우스가 의도한 것보다 더 멀리 움직이는 것을 확인했어요.
- 사이드바에 확대 버튼이 있음에도 미세한 조작이 어렵고 사이드바의 버튼들이 인접해 있어 종료 버튼과 도움말 버튼을 실수로 클릭하는 경우가 있었어요.
- 일시 정지 버튼이 사이드바와 카메라 화면을 완전히 숨기지 않고 마우스 방향 제어와 깜빡임 제어에서 벗어나지 않는 문제도 해결해야 해요.
- 설정 페이지에서 스크롤 감도를 직접 설정할 수 있으면 좋겠다는 의견과 변수의 범위를 자연수로 통일하면 시스템 사용이 더 직관적일 것이라는 의견도 공유됐어요.
수정 결과
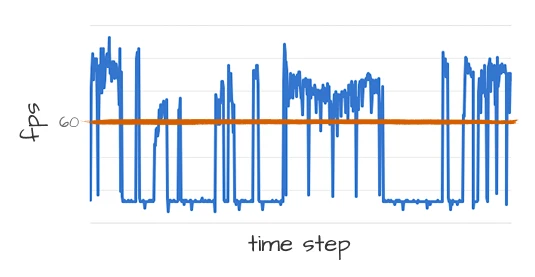
프레임 드랍. 프레임 드랍은 CPU가 모든 연산을 처리하지 못할 때 발생하는 지연이에요. 문제를 해결하기 위해 머리 회전 시 FPS를 측정했어요. 그 결과 Pyautogui로 방향을 제어할 때 가장 큰 프레임 드랍이 발생하는 것을 확인했어요. 하지만 그래프에서 볼 수 있듯이 드랍이 발생할 때의 FPS는 연속적이지 않아요. 따라서 프레임 속도를 제한함으로써 문제를 해결했어요.
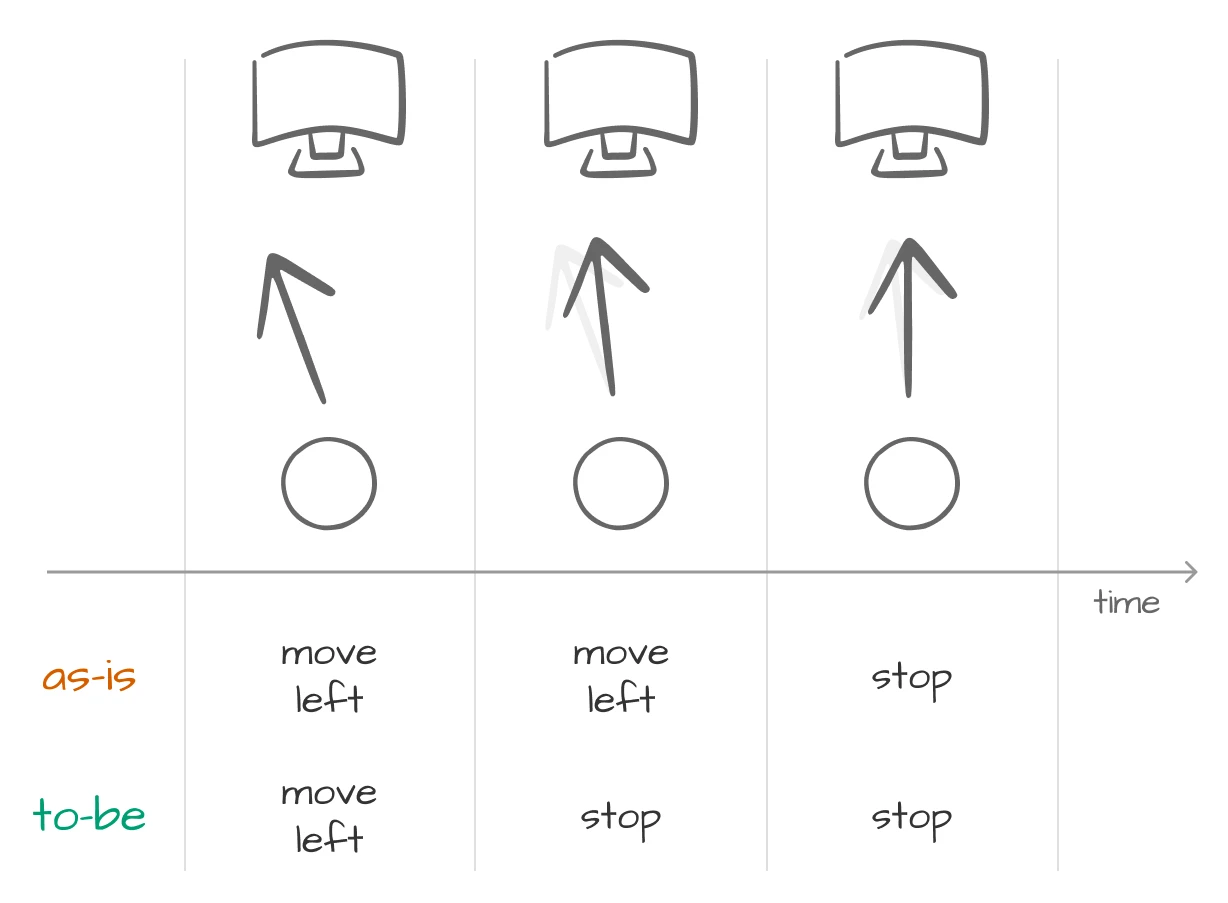
머리 움직임. 이전에는 각 방향의 임계값 이상으로 머리를 돌리면 마우스가 무조건 움직였어요. 그러나 마우스를 멈추고 싶을 때 마우스가 미끄러지듯 움직이는 문제가 있었어요. 이를 해결하기 위해 현재 프레임의 각도가 이전 프레임에서 계산된 각도와 현재 각도의 변화율을 계산했어요. 변화율이 3도 이상이면, 마우스가 멈추도록 설정했어요. 따라서 머리가 중앙으로 빠르게 돌아갈 때 마우스가 덜 움직이게 돼요.
그 외에도 사이드바, 설정 페이지 UI 등 수정이 있었어요.
2차 테스트 결과
수정한 기능이 제대로 작동하는지 확인하기 위해 비장애인 사용자 7명을 대상으로 2차 테스트를 수행했어요. 이번에는 간소화된 검증을 위해 세 가지 과제를 완료했으며 참가자들에게 “프레임 드랍 발생” 및 “의도치 않은 마우스 움직임”에 대해 추가적으로 질문했어요. 첫 테스트에서 확인된 ‘프레임 드랍으로 인한 지연’과 ‘멈출 때 마우스가 미끄러지는 현상’은 해결되었어요. 그러나 여전히 작은 버튼을 누르기 어렵다고 했어요. 이로 인해 웹사이트 내의 작은 버튼과 상호작용하기 어려워 여러 번의 시도가 필요했어요. 참가자들의 공통적인 제안은 머리 움직임의 정도에 따라 커서 이동 속도가 바뀌도록 구현하는 것이었어요. 고개를 많이 돌리면 커서가 빠르게 미끄러지는 식이죠.
장애인 사용자 연구
접근성 개선을 평가하기 위해 손 떨림을 겪는 사용자와 세 번째 테스트를 진행했어요. 이 세션 동안 사용자는 아래 방향 커서 움직임에 어려움을 느꼈다고 답했어요. 사이드바와 같은 특정 인터페이스 요소가 상호작용을 방해한다고 지적했고 특히 유튜브 전체 화면 토글에 접근하는 문제를 언급했어요. 또한 웹툰 보기와 같은 과제를 완료하는 동안 스크롤 버튼을 반복적으로 클릭하는 것이 불편하다고 느꼈어요. 이러한 사용성 문제는 방향 제어 개선과 시각적 방해를 줄이기 위한 UI 조정의 필요성을 시사해요. 또한 마우스 전용 상호작용이 여전히 한계가 있음을 지적하며 키보드를 대처할 수 있는 기능까지 확장할 것을 제안했어요. 향후 개발에서는 키보드 에뮬레이션 기능과 커서 제어 감도를 개선해야 할 것으로 보여요.
전문가 피드백
Palette팀의 얼굴 인식 활용 대체 입력 프로젝트가 매우 잘 수행되었습니다. 특히 기존의 연구나 상품들이 제공하지 못했던 여러 기법들을 머신러닝과 딥러닝 기술로 잘 활용하여 저렴한 비용으로 사용할 수 있도록 새로운 방식을 잘 제안하였다고 판단됩니다. - Microsoft 김대우 이사

Team Palette 이야기
팔레트는 주인공이 되기보단, 주인공이 가장 잘 빛날 수 있도록 바탕을 만들어주는 도구에요. 자신이 주인공은 아니지만, 물감 하나하나가 아름답게 빛날 수 있도록 돕는 존재죠. 저희 소프트웨어는 주인공이 되려는 것이 아닙니다. 사용자 한 사람 한 사람이 주인공이 되어 빛날 수 있도록 조용히 곁에서 돕는 것이 저희의 목표에요. 화려하지는 않지만, 기술을 통해 더 많은 사람이 편안하게 일상을 살아갈 수 있도록 보이지 않는 곳에서 함께하고 싶어요. - Team Palette
저희는 소프트웨어는 독창성을 인정받아 특허로 등록되었으며, 소스코드는 오픈소스로 공개했어요. FaceMouse가 접근성 기술 발전에 작은 기여가 되었으면 해요.
(+ 2026) FaceMouse는 2022년 초에 개발되었어요. 시간이 지나 LLM이 등장했어요. FaceMouse의 한계를 극복하기 위해 LLM을 활용한 시스템도 시도해 봤어요. 자세한 이야기는 Speak2UI로 이어져요.