모바일 제어를 위한 음성 파이프라인 최적화
Github: Jin-A-Park/Speak2UI
Demo: speak2ui_demo.mp4
이 프로젝트는 실시간으로 음성 명령을 입력받아 LLM으로 사용자 명령을 분석하고, Android A11y API를 통해 동작을 실행해요. 안드로이드 단에서 정보를 불러오고 조작하는 코드는 주로 Jin-A-Park님께서 작업했으며, 저는 주로 LLM 기반 명령 해석 모듈의 개발 및 실험을 담당했어요. 추가로 음성 파이프라인 최적화와 코드 리팩토링을 맡았어요. LLM 단의 작업은 뻔한 내용이라, 이 글에서는 음성 파이프라인을 최적화해야 했던 이유와 방법을 중심으로 소개할게요.
왜 하필 음성인가요
처음에는 시선 추적을 이용해 화면을 조작하려 했어요. 하지만 시선 추적의 정확도가 높지 않았고, 정확한 시선 추적이 된다 해도 모바일 상의 버튼이 너무 작아서 정밀한 조작이 어렵다고 판단했어요. 그래서 버튼의 물리적인 크기에 구애받지 않는 인터페이스가 필요했고, 결국 음성 명령에 도달했어요. 음성으로 조작하기 위해서는 화면 상에 상호작용 가능한 요소를 파싱하고, 사용자의 명령을 어떤 요소와 매핑할지 실시간으로 추론해야 했어요. 그래서 우리 팀은 tooltip과 LLM을 활용하기로 했죠.
상호작용 가능한 요소를 정확히 매핑하기 위해 레이블이 명확하지 않은 요소는 실시간으로 숫자를 매기도록 했어요. 이 기능을 tooltip이라고 이름 붙였어요. 사용자 명령이 어떤 요소를 의도했는지 판단하는 데는 LLM의 추론 능력을 활용했어요. 자세한 구현은 논문(공개 예정)에서 확인할 수 있어요. 이 방식을 통해 버튼의 물리적인 크기에 제약받지 않으면서도 직관적인 인터페이스를 제공할 수 있답니다.
음성 인식 왜 이렇게 느려요
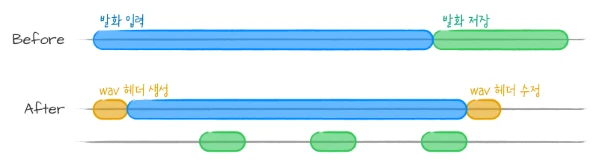
제가 음성 처리 파이프라인 쪽으로 넘어갔을 때, VAD가 구현되어 있었지만 짧은 발화를 인식하는 데 10초가 걸렸어요. 처음에 의심했던 부분은 I/O로 인한 딜레이였어요. 사용자 발화를 메모리에 모두 저장했다가 발화가 종료되면 wav 파일로 저장되기 때문에, 메모리에서 디스크로 저장하는 과정에서 딜레이가 발생할 거라 생각했죠. 그래서 한 번에 wav로 저장하는 대신 실시간으로 디스크에 음성 정보를 밀어넣고, 입력이 끝나면 wav 포맷으로 재구성하는 방식을 이용해 I/O 딜레이를 해결했어요. 그림으로 표현하면 아래와 같아요.
하지만 여전히 음성 처리에 10초가 걸렸어요. 문제를 디버깅해보니 VAD 자체에 문제가 있었어요. VAD는 특정 크기(db) 이상의 소리가 들리면 사용자가 발화를 시작했다고 판단해요. 그런데 소음을 판단하는 기준(threshold)이 낮게 설정되어 있으면 잡음까지 발화라고 인식하는 현상이 생겼어요. 추가로 시스템에서 발화의 최대 길이를 10초로 제한해뒀기 때문에 음성 인식에 항상 10초가 걸렸던 거예요. 해결 방법은 간단해요. 음성 인식을 받기 전 짧게 주변 소음 수준을 인식해 동적으로 임계값을 조절하면 돼요. 그럼 완벽하진 않지만 주변의 소음 수준을 지속적으로 반영할 수 있게 돼요. 이 방식을 적용했더니 10초가 걸리던 음성 인식을 1초대로 단축할 수 있었어요.
말귀를 못 알아 들어요
마지막으로 실사용성을 확인하기 위해 IRB 승인 하에 실험을 진행했어요. 사용자에게 영상 재생, 네비게이션 검색, 채팅 전송 3가지 과제를 수행하도록 하고 관찰 실험과 설문을 진행했어요. 8명의 실험 참가자는 모두 한국어를 사용해 명령을 수행했어요. 그런데 생각보다 명령이 의도한 대로 처리되지 못했죠. 실시간으로 로그를 뜯어보니 STT 단계가 문제였어요. 애초에 오디오가 텍스트로 정확히 변환되지 않으니 그 뒤에 일어나는 과정도 제대로 수행되지 않았어요. 빠르고 저렴하게 처리하기 위해 gpt-4o-mini-transcribe를 사용했는데, 아직 부정확한 한국어 발음은 잘 처리하지 못하는 모양이에요. STT 모듈은 쉽게 변경할 수 있기 때문에 상황에 맞는 적절한 모델을 선택해 성능 개선을 기대할 수 있어요.