Diffusion, DDPM and DDIM
Diffusion은 최근 이미지 생성 분야의 표준처럼 자리 잡은 모델이에요. 논문을 읽다보면 diffusion이나 flow matching에 대한 이야기가 나오는데, 학교에서 관련 강의가 열리지 않아 Stanford Online으로 공부를 시작했어요. 이 글에서는 Stanford CME 296의 1강 내용을 바탕으로, Diffusion이 어떤 원리로 이미지를 만드는지 수식과 함께 차근차근 풀어볼게요.
Diffusion은 왜 노이즈에서 시작할까
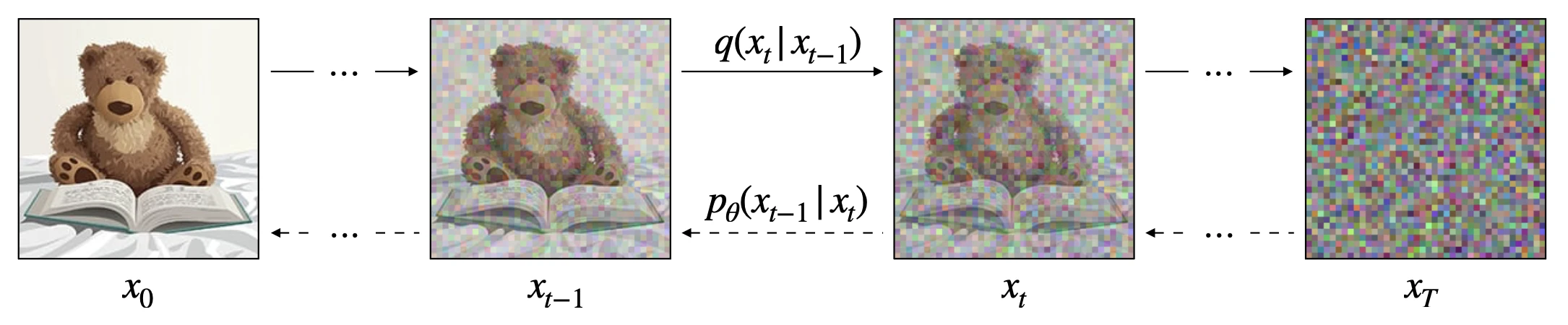
우리의 목표는 주어진 이미지 데이터 분포에서 새로운 이미지를 생성하는 거예요. 그런데 왜 하필 의미 없는 노이즈에서 출발할까요?
- 노이즈는 샘플링이 쉬워요. 뒤에서 설명할 가우시안 분포에서 한 번 뽑기만 하면 돼요.
- 무작위성을 자연스럽게 포함해서 매번 다른 이미지를 만들 수 있어요.
- 가우시안 분포는 평균, 분산, 두 분포 사이의 거리까지 수식으로 깔끔하게 다뤄져요. 이 성질 덕분에 나중에 수식 유도가 극적으로 단순해져요.
Diffusion 모델은 불필요한 노이즈를 조금씩 깎아내는 방법을 배워요. 이제 이 아이디어를 수식으로 바꾸기 위해 필요한 배경지식부터 정리해볼게요.
확률 분포를 되짚어요
Diffusion을 이해하려면 확률 분포에 대한 몇 가지 도구가 필요해요. 이미 익숙하다면 건너뛰어도 괜찮지만, 뒤에서 나올 수식이 어디서 왔는지 궁금해질 때 다시 돌아오면 좋아요.
가우시안 분포에 대해
가우시안 분포(Gaussian distribution), 또는 정규분포는 자연 현상에서 자주 등장하는 종 모양의 확률 분포예요. 1차원에서 평균 $\mu$와 분산 $\sigma^2$로 특징지어져요. 확률 밀도 함수는 다음과 같아요.
\[p(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(x - \mu)^2}{2\sigma^2}\right)\]- $\mu$는 분포의 중심이에요. 값을 뽑으면 이 근처가 가장 자주 나와요.
- $\sigma^2$는 퍼짐의 정도예요. 크면 넓게 퍼지고, 작으면 뾰족하게 모여요.
- $\exp$ 안의 $-(x-\mu)^2$는 중심에서 멀어질수록 확률이 빠르게 작아지게 해요.
- 앞의 $\frac{1}{\sqrt{2\pi\sigma^2}}$는 전체 적분이 1이 되도록 맞춰주는 정규화 상수예요.
이미지처럼 고차원 데이터에서는 벡터로 확장돼요. $d$차원 벡터 $x$에 대한 다변량 가우시안은 다음과 같이 써요.
\[x \sim \mathcal{N}(\mu, \Sigma)\]- $\mu \in \mathbb{R}^d$는 평균 벡터예요.
- $\Sigma \in \mathbb{R}^{d \times d}$는 공분산 행렬이에요. 대각 원소 $\Sigma^{(i,i)}$는 $i$번째 차원의 분산이고, 비대각 원소 $\Sigma^{(i,j)}$는 $i$번째와 $j$번째 차원이 어떻게 같이 움직이는지(공분산) 나타내요.
등방성 가우시안은 왜 편리할까
Diffusion에서는 주로 등방성(isotropic) 가우시안을 써요. 공분산 행렬이 $\Sigma = \sigma^2 I$ 형태예요. $I$는 단위 행렬이고, 모든 방향으로 분산이 같다는 뜻이에요.
\[p(x) = \frac{1}{(2\pi\sigma^2)^{d/2}} \exp\left(-\frac{\|x - \mu\|^2}{2\sigma^2}\right)\]왜 편리할까요? 일반적인 가우시안은 $d \times d$ 크기의 공분산 행렬을 다뤄야 해요. $d$가 수만 차원인 이미지에서는 역행렬 계산이 거의 불가능해요. 반면 등방성 가우시안은 스칼라 $\sigma^2$만 있으면 되고, 각 차원이 독립이기 때문에 한 차원씩 따로 샘플링해서 합치는 방식으로도 처리할 수 있어요.
결합, 조건부, 주변 확률을 구분해요
여러 변수를 다룰 때는 세 종류의 확률을 구분해야 해요.
- 결합(joint) 확률 $p(x, y)$: $x$와 $y$가 동시에 일어날 확률이에요.
- 조건부(conditional) 확률 $p(x \mid y)$: $y$를 알고 있을 때 $x$의 확률이에요.
- 주변(marginal) 확률 $p(x)$: 다른 변수를 평균 내서 없앤 $x$ 단독의 확률이에요.
세 확률은 하나의 식으로 연결돼요.
\[p(x, y) = p(x \mid y) \cdot p(y) = p(y \mid x) \cdot p(x)\]여기서 마지막 등식을 재정리하면 유명한 베이즈 정리가 나와요.
\[p(x \mid y) = \frac{p(y \mid x)\, p(x)}{p(y)}\]그리고 여러 시점의 결합 확률은 조건부 확률의 곱으로 풀어 쓸 수 있어요.
\[p(x_1, x_2, \ldots, x_T) = p(x_1) \cdot p(x_2 \mid x_1) \cdots p(x_T \mid x_1, \ldots, x_{T-1})\]이 표현을 Diffusion에서 수없이 사용해요. 한 변수를 없애는 과정인 주변화(marginalization) 는 적분으로 이뤄져요.
\[p(x_1) = \int p(x_1, x_2, \ldots, x_T) \, dx_2 \cdots dx_T\]여러 시점의 모든 가능한 값을 다 더해서 $x_1$ 하나만 남기는 셈이에요. 뒤에서 “로그 가능도 계산이 어렵다”고 말할 때, 바로 이 적분이 불가능에 가깝다는 뜻이에요.
Forward process는 이미지를 서서히 망가뜨려요
이제 본론으로 들어갈게요. Diffusion은 두 단계로 구성돼요.
- Forward process: 깨끗한 이미지 $x_0$에 노이즈를 조금씩 더해 $x_T \approx \epsilon$이 될 때까지 망가뜨려요.
- Reverse process: 망가진 $x_T$에서 다시 깨끗한 $x_0$로 되돌리는 과정을 신경망이 학습해요.
Forward는 우리가 직접 설계하기 때문에 수식으로 완전히 알 수 있어요. 시점 $t-1$에서 $t$로 노이즈를 한 스텝 더하는 공식은 다음과 같아요.
\[q(x_t \mid x_{t-1}) = \mathcal{N}\left(\sqrt{1 - \beta_t}\, x_{t-1},\; \beta_t I\right)\]읽는 법을 풀어 볼게요. “이전 이미지 $x_{t-1}$이 주어졌을 때, 다음 이미지 $x_t$는 평균이 $\sqrt{1-\beta_t}\, x_{t-1}$이고 분산이 $\beta_t I$인 가우시안에서 뽑힌다”는 뜻이에요. 구체적으로는 이런 연산이에요.
\[x_t = \sqrt{1 - \beta_t}\; x_{t-1} + \sqrt{\beta_t}\; \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\]표준 가우시안 $\epsilon$에서 뽑은 노이즈를 더하는 거예요. 가우시안을 $\mu + \sigma \epsilon$ 형태로 쓰는 기법을 재매개변수화(reparameterization) 라고 불러요. 샘플링 과정을 결정론적 연산과 표준 노이즈로 분리할 수 있어서 나중에 역전파를 태우기 쉬워져요.
계수에 대해
두 계수에는 의도가 숨어 있어요. 먼저 이전 이미지의 신호가 얼마나 남는지 생각해봐요. 평균이 $\sqrt{1-\beta_t}\, x_{t-1}$이므로 신호의 크기는 대략 $\sqrt{1-\beta_t}$배로 줄어요. 동시에 $\beta_t$만큼의 분산으로 노이즈가 새로 섞여요. 두 값을 제곱해서 더하면 정확히 1이 돼요.
\[(1 - \beta_t) + \beta_t = 1\]즉, 신호의 에너지와 노이즈의 에너지를 합친 총 에너지가 보존돼요. 이렇게 해야 $t$가 커져도 $x_t$의 분산이 폭발하거나 소실되지 않고 일정한 스케일로 유지돼요. 이 설계 덕분에 $x_T$의 분포가 결국 단위 가우시안 $\mathcal{N}(0, I)$에 가까워져요.
$\beta_t$는 시간이 갈수록 커지도록 스케줄해요.
\[0 \leq \beta_1 < \beta_2 < \cdots < \beta_T \leq 1\]작은 $t$에서는 $\beta_t$가 매우 작아서 거의 원래 이미지예요. $t$가 커질수록 노이즈 비율이 올라가고, 결국 $T$에서는 이미지가 거의 보이지 않는 순수 노이즈가 돼요. $\beta_t$의 구체적인 값을 정하는 방식을 noise schedule이라고 해요. 선형으로 증가시키거나, 코사인 곡선처럼 완만하게 증가시키는 선택지가 있어요.
한 번에 $x_t$로 건너뛰는 공식이 필요해요
학습할 때 임의의 시점 $t$에서 $x_t$를 만들어야 해요. 그런데 정의 그대로라면 $x_0$부터 $t$번의 스텝을 하나씩 거쳐야 하죠. $T$가 1000 정도라면 너무 비효율적이에요.
다행히 가우시안 노이즈에는 멋진 성질이 있어요. 독립인 가우시안들의 합은 다시 가우시안이 된다는 거예요. 구체적으로, $X \sim \mathcal{N}(\mu_X, \sigma_X^2)$과 $Y \sim \mathcal{N}(\mu_Y, \sigma_Y^2)$가 서로 독립이면 다음이 성립해요.
\[X + Y \sim \mathcal{N}(\mu_X + \mu_Y,\; \sigma_X^2 + \sigma_Y^2)\]평균과 분산이 그냥 더해지는 거예요. 이 성질을 Forward process의 정의에 재귀적으로 대입하면, $x_0$에서 $x_t$로 한 번에 건너뛰는 공식을 얻을 수 있어요.
\[q(x_t \mid x_0) = \mathcal{N}\left(\sqrt{\bar{\alpha}_t}\, x_0,\; (1 - \bar{\alpha}_t)\, I\right)\]여기서 새로운 기호가 등장해요.
\[\alpha_t = 1 - \beta_t, \qquad \bar{\alpha}_t = \prod_{i=1}^{t} \alpha_i\]- $\alpha_t = 1 - \beta_t$는 “한 스텝에서 신호가 얼마나 살아남는지”를 나타내요. $\beta_t$가 작을수록 $\alpha_t$는 1에 가까워요.
- $\bar{\alpha}_t$는 $\alpha_1$부터 $\alpha_t$까지 곱한 값이에요. “지금까지 누적된 신호 생존율”이라고 볼 수 있어요. $t$가 커질수록 0에 가까워져요.
풀어 쓰면, 임의의 $t$에 대해 다음과 같이 $x_t$를 한 줄에 만들 수 있어요.
\[x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)\]이 식이 학습 과정에서 핵심이 돼요. 어떤 $t$가 주어지든 한 번의 계산으로 $x_t$를 만들 수 있고, 그때 더해진 노이즈 $\epsilon$도 정확히 알고 있어요.
Reverse process는 학습으로 풀어야 해요
Forward는 우리가 설계한 과정이라 모든 것을 알고 있어요. 하지만 역방향 $q(x_{t-1} \mid x_t)$는 직접 계산할 수 없어요. 왜 그럴까요?
$x_t$만 보고 $x_{t-1}$을 맞추려면, 결국 “노이즈가 조금 섞인 이미지가 원래 어떤 이미지였을지”를 추정해야 해요. 이건 데이터 분포 $q(x_0)$를 알아야 풀 수 있는 문제예요. 세상의 모든 고양이 사진, 풍경 사진의 분포를 수식으로 알고 있다면 계산할 수 있지만, 당연히 우리는 모르죠. 알고 있다면 애초에 생성 모델이 필요하지 않아요.
그래서 파라미터 $\theta$를 가진 신경망으로 이 역과정을 근사해요.
\[p_\theta(x_{t-1} \mid x_t) = \mathcal{N}\left(\mu_\theta(x_t, t),\; \Sigma_\theta(x_t, t)\right)\]모델이 가우시안의 평균과 분산을 출력하도록 만들어요. 우리가 원하는 건 결국 학습 이미지의 로그 가능도를 최대화하는 $\theta$예요.
\[\max_\theta \; \log p_\theta(x_0)\]로그를 씌우는 건 두 가지 이유 때문이에요. 첫째, 로그는 단조 증가 함수라서 $p_\theta(x_0)$를 최대화하는 $\theta$와 $\log p_\theta(x_0)$를 최대화하는 $\theta$는 같아요. 둘째, 확률은 아주 작은 값들의 곱이라 그대로 다루면 수치적으로 불안정해요. 로그를 씌우면 곱이 합으로 바뀌고 계산이 안정돼요.
왜 로그 가능도를 직접 다루기 어려울까
문제는 $\log p_\theta(x_0)$를 계산하려면 모든 가능한 중간 경로 $x_1, \ldots, x_T$를 적분해야 한다는 거예요.
\[p_\theta(x_0) = \int p_\theta(x_0, x_1, \ldots, x_T) \, dx_1 \cdots dx_T\]이 적분은 사실상 계산이 불가능해요. $x_t$가 수만 차원 벡터이고, $T$가 1000쯤 되니까 적분 공간이 천문학적이에요. 이걸 주변화가 intractable하다고 표현해요.
그래서 $\log p_\theta(x_0)$ 대신, 계산 가능한 하한(lower bound) 을 만들어 그 하한을 최대화해요. 하한을 올리면 원래 값도 최소한 그만큼은 올라가니까요. 이 아이디어를 구체화한 것이 변분 추론(variational inference) 이고, 결과물이 ELBO예요.
ELBO를 네 단계로 유도해봐요
Diffusion 논문을 읽다가 처음 마주치는 장벽이 바로 이 수식 유도예요. 하지만 큰 흐름은 네 단계로 단순해요. 각 단계가 어떤 수학적 도구를 쓰는지 정리하면서 가볼게요.
1단계: Jensen 부등식으로 하한을 얻어요
Jensen 부등식은 오목 함수(concave function)의 성질을 다루는 부등식이에요. $f$가 오목 함수일 때 다음이 성립해요.
\[f(\mathbb{E}[X]) \geq \mathbb{E}[f(X)]\]기댓값을 먼저 씌우고 $f$를 적용한 값이, $f$를 먼저 씌우고 기댓값을 취한 값보다 크거나 같다는 뜻이에요. 직관적으로는 위로 볼록한 종 모양 함수에서 점들의 평균이 함수값들의 평균보다 위에 있다는 얘기예요. 로그 함수 $\log$는 대표적인 오목 함수예요.
로그 가능도에 이 부등식을 적용하기 위해, 가능도 식에 임의의 분포 $q$를 곱했다가 나누는 트릭을 써요.
\[\log p_\theta(x_0) = \log \int p_\theta(x_{0:T}) \, dx_{1:T} = \log \int q(x_{1:T} \mid x_0) \cdot \frac{p_\theta(x_{0:T})}{q(x_{1:T} \mid x_0)} \, dx_{1:T}\]그리고 적분을 기댓값으로 다시 쓰면 이렇게 돼요.
\[\log p_\theta(x_0) = \log \mathbb{E}_{x_{1:T} \sim q(x_{1:T} \mid x_0)}\left[\frac{p_\theta(x_{0:T})}{q(x_{1:T} \mid x_0)}\right]\]여기에 Jensen 부등식을 적용해서 $\log$를 기댓값 안으로 옮기면 부등호 방향이 보장돼요.
\[\log p_\theta(x_0) \geq \mathbb{E}_{x_{1:T} \sim q(x_{1:T} \mid x_0)}\left[\log \frac{p_\theta(x_{0:T})}{q(x_{1:T} \mid x_0)}\right]\]이 우변이 바로 ELBO (Evidence Lower BOund) 예요. “Evidence”는 $p_\theta(x_0)$의 또 다른 이름인 증거(evidence) 에서 왔고, 이 증거의 로그에 대한 하한이라는 뜻이에요. Diffusion에서는 Forward process의 분포 $q$를 그대로 $q(x_{1:T} \mid x_0)$로 사용해요. 우리가 이미 알고 있는 분포니까 계산이 쉬워요.
2단계: ELBO를 전개해서 KL divergence를 드러내요
1단계의 ELBO를 그대로 최대화하기엔 $T$개의 시점이 뒤엉켜 있어요. 이걸 시점별로 쪼개서 손에 잡히는 형태로 풀어볼게요.
Forward process가 마르코프(Markov) 성질을 가진다는 점을 이용해요. 마르코프 성질이란 현재 상태가 주어지면 모든 과거 상태가 필요 없다는 성질이에요. Diffusion에서는 $q(x_t \mid x_{t-1}, x_{t-2}, \ldots) = q(x_t \mid x_{t-1})$처럼 바로 이전 시점만 보면 충분해요. 덕분에 결합 확률이 간단한 곱으로 풀려요.
\[q(x_{1:T} \mid x_0) = \prod_{t=1}^{T} q(x_t \mid x_{t-1})\] \[p_\theta(x_{0:T}) = p(x_T) \prod_{t=1}^{T} p_\theta(x_{t-1} \mid x_t)\]이걸 ELBO 식에 넣고, 로그의 곱을 합으로 풀고, 항들을 재배열하면 다음과 같은 형태가 나와요.
\[\text{ELBO} = -\sum_{t=2}^{T} \mathbb{E}_q\left[\text{KL}\Big(q(x_{t-1} \mid x_t, x_0) \,\|\, p_\theta(x_{t-1} \mid x_t)\Big)\right] + (\text{extra terms})\]핵심 결과만 남았어요. 각 시점 $t$마다 하나의 KL divergence 항이 등장해요.
KL divergence는 두 확률 분포가 얼마나 다른지를 보여주는 지표예요. 분포 $p$와 $q$에 대해 다음과 같이 정의돼요.
\[\text{KL}(p \| q) = \mathbb{E}_{x \sim p}\left[\log \frac{p(x)}{q(x)}\right]\]$p$에서 뽑은 샘플이 $q$에서 나올 만한 값인지 로그 비율로 재는 개념이에요. 0이면 두 분포가 같고, 멀어질수록 커져요. 단 대칭적이지 않아서 $\text{KL}(p | q) \neq \text{KL}(q | p)$예요. 그래서 엄밀히는 “거리”가 아니라 “divergence”라고 불러요.
ELBO를 최대화하려면 이 KL 항을 최소화해야 해요. 그러니까 학습은 $q(x_{t-1} \mid x_t, x_0)$와 $p_\theta(x_{t-1} \mid x_t)$가 서로 가깝도록 $\theta$를 조정하는 문제가 돼요.
3단계: $q(x_{t-1} \mid x_t, x_0)$을 계산 가능하게 만들어요
2단계의 KL 항을 계산하려면 $q(x_{t-1} \mid x_t, x_0)$을 알아야 해요. 이 분포는 “Forward의 역방향이지만 $x_0$을 알고 있는 경우”에 해당해요. 신기하게도 이 조건부 분포는 닫힌 형태로 계산할 수 있어요.
베이즈 정리를 한 번 쓰면 이렇게 풀려요.
\[q(x_{t-1} \mid x_t, x_0) = \frac{q(x_t \mid x_{t-1}, x_0) \cdot q(x_{t-1} \mid x_0)}{q(x_t \mid x_0)}\]각 항이 우리가 이미 아는 값이에요.
- $q(x_t \mid x_{t-1}, x_0) = q(x_t \mid x_{t-1})$: 마르코프 성질로 $x_0$를 지울 수 있어요. 앞서 본 Forward 한 스텝 공식이에요.
- $q(x_{t-1} \mid x_0)$: 앞서 유도한 한 번에 건너뛰는 공식이에요.
- $q(x_t \mid x_0)$: 같은 공식을 $t$에 적용한 결과예요.
세 가우시안의 곱과 나눔을 정리하면, 결과도 가우시안이에요. 가우시안의 지수부 이차식을 $(x_{t-1})$에 대해 제곱완성하면 평균과 분산이 깔끔하게 떨어져요.
\[q(x_{t-1} \mid x_t, x_0) = \mathcal{N}(\tilde{\mu}_t, \tilde{\beta}_t I)\]평균은 다음과 같이 나와요 (식 유도는 강의에서도 생략했어요).
\[\tilde{\mu}_t = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}}\, \epsilon_t\right)\]여기서 $\epsilon_t$는 $x_0$에서 $x_t$로 갈 때 실제로 더해진 노이즈예요. 즉 “현재 상태 $x_t$에서 실제 더해진 노이즈를 빼고 적절히 스케일하면 이전 상태의 평균”이라는 식이에요. 모델이 할 일은 이 $\epsilon_t$를 추정하는 것뿐이에요.
4단계: 두 가우시안의 KL divergence로 loss를 얻어요
모델 $p_\theta(x_{t-1} \mid x_t)$도 가우시안으로 가정했어요. 그러니 2단계의 KL 항은 결국 두 가우시안 사이의 KL divergence가 돼요. 두 가우시안 $\mathcal{N}(\mu_1, \sigma^2 I)$와 $\mathcal{N}(\mu_2, \sigma^2 I)$의 KL divergence는 유명한 닫힌 형태예요.
\[\text{KL}\Big(\mathcal{N}(\mu_1, \sigma^2 I) \,\|\, \mathcal{N}(\mu_2, \sigma^2 I)\Big) = \frac{\|\mu_1 - \mu_2\|^2}{2\sigma^2}\]분산이 같다면 결국 평균의 차이의 제곱에 비례해요. DDPM 논문에서는 모델의 분산을 고정값으로 두고, 평균만 학습하도록 설계했어요. 그리고 평균 자체를 직접 예측하는 대신, 평균을 다시 파라미터화해서 노이즈를 예측하도록 바꿨어요. 3단계의 $\tilde{\mu}_t$ 식을 보면 알 수 있듯이, $\epsilon_t$만 맞추면 평균은 자동으로 맞아요.
두 평균을 정리해볼게요. 먼저 $\mu_1$은 3단계에서 유도한 $\tilde{\mu}_ t$예요. 이 값은 학습 과정에서 실제로 더해진 노이즈 $\epsilon$을 이용해 계산돼요. $\mu_2$는 모델이 예측한 평균 $\mu_\theta$예요. 이 값은 모델이 예측한 노이즈 $\epsilon_\theta$를 같은 공식에 대입해서 만들어요.
\[\mu_1 = \tilde{\mu}_t = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}}\, \epsilon\right)\] \[\mu_2 = \mu_\theta = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}}\, \epsilon_\theta\right)\]두 식은 노이즈 자리에 들어가는 값만 다르고 나머지는 완전히 같아요. 그래서 둘의 차이를 구하면 $x_t$ 항과 $\frac{1}{\sqrt{\alpha_t}}$ 배율이 깨끗하게 상쇄되고, 노이즈의 차이 $\epsilon - \epsilon_\theta$에 비례하는 항만 남아요.
\[\mu_1 - \mu_2 = \frac{1}{\sqrt{\alpha_t}} \cdot \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \cdot (\epsilon - \epsilon_\theta)\]이 차이를 KL 공식에 대입하면 $|\mu_1 - \mu_2|^2$이 결국 $|\epsilon - \epsilon_\theta|^2$에 어떤 상수 계수를 곱한 형태가 돼요. 모델 학습에서 상수 계수는 최적화 방향에 영향을 주지 않아서 통째로 생략해도 괜찮아요. 이렇게 모든 상수를 떼어내고 남은 최종 loss는 놀랄 만큼 단순해요.
\[x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \epsilon\] \[\mathcal{L}_{\text{DDPM}} = \mathbb{E}_{t, x_0, \epsilon}\left[\left\| \epsilon_\theta(x_t, t) - \epsilon \right\|^2\right]\]조건은 다음과 같아요.
\[t \sim \mathcal{U}\{1, T\}, \qquad x_0 \sim q_0(x_0), \qquad \epsilon \sim \mathcal{N}(0, I)\]시점 $t$는 균등 분포에서, 이미지 $x_0$는 데이터에서, 노이즈 $\epsilon$은 표준 가우시안에서 뽑아요. 모델은 노이즈 섞인 이미지 $x_t$와 시점 $t$를 입력받아, 추가된 노이즈 $\epsilon$을 맞히도록 학습돼요. 복잡한 변분 추론이 뒤에 숨어 있지만, 실제 loss는 평범한 MSE 하나예요.
학습은 단순한 노이즈 맞추기예요
4단계에서 유도한 loss 식을 그대로 학습 루틴으로 바꾸면 이런 흐름이에요.
- 데이터에서 깨끗한 이미지 $x_0$를 하나 뽑아요.
- 시점 $t$를 ${1, \ldots, T}$에서 균등하게 뽑아요.
- 표준 가우시안에서 노이즈 $\epsilon$을 뽑아요.
- 한 번에 건너뛰는 공식 $x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \epsilon$으로 노이즈 이미지를 만들어요.
- 모델에 $(x_t, t)$를 넣어 예측 노이즈 $\epsilon_\theta(x_t, t)$를 얻어요.
- 예측 노이즈와 실제 $\epsilon$ 사이의 제곱오차를 계산하고 역전파해요.
모델 구조는 보통 U-Net을 써요. 이미지와 같은 크기의 노이즈를 예측해야 하니 encoder-decoder 구조에 skip connection이 있는 U-Net이 자연스러워요. 시점 $t$는 sinusoidal embedding으로 벡터화해서 모델 중간에 주입해요.
추론은 노이즈에서부터 거꾸로 걸어요
학습이 끝나면 순수 노이즈 $x_T \sim \mathcal{N}(0, I)$에서 시작해 한 스텝씩 거꾸로 내려와요. 업데이트 공식은 다음과 같아요.
\[x_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}}\, \epsilon_\theta(x_t, t)\right) + \sigma_t z, \qquad z \sim \mathcal{N}(0, I)\]복잡해 보이지만 각 부분의 역할을 따라가면 읽을 수 있어요.
- 괄호 안의 뺄셈: 현재 $x_t$에서 예측한 노이즈 $\epsilon_\theta(x_t, t)$를 적당히 스케일해 빼는 부분이에요. 이게 “노이즈를 깎아낸다”는 직관에 해당해요. 3단계에서 유도한 $\tilde{\mu}_t$ 식과 완전히 같은 구조예요.
- 앞의 $\frac{1}{\sqrt{\alpha_t}}$ 배율: 신호의 크기를 원래대로 되돌리는 역할이에요. Forward에서 $\sqrt{\alpha_t}$배로 줄였으니 역방향에서는 그 역수만큼 키워요.
- 뒤의 $\sigma_t z$: 무작위성을 약간 다시 주입해요. ELBO 유도 과정에서 $p_\theta$를 가우시안으로 가정했기 때문에, 평균만 찍지 않고 샘플링을 해야 분포 전체를 제대로 흉내내게 돼요. 다만 마지막 스텝에서는 이 항을 제거하고 평균만 취해요.
이 과정을 $t = T, T-1, \ldots, 1$까지 반복하면 최종 이미지 $x_0$를 얻어요. 매 스텝마다 모델 $\epsilon_\theta$를 한 번씩 호출해야 해요.
DDPM은 추론이 너무 느려요
지금까지 설명한 접근이 바로 DDPM (Denoising Diffusion Probabilistic Models) 이에요. Ho et al. (2020)의 기념비적인 논문이에요. 학습은 단순하지만 추론이 느리다는 단점이 있어요.
- 보통 $T = 1000$ 스텝 전체를 순회해야 해요.
- VAE나 GAN이 한 번의 forward pass로 끝나는 것에 비해 수백~수천 배 느려요.
- 고해상도 이미지 한 장에 수 분이 걸릴 수 있어요.
그럼 스텝을 건너뛰면 되지 않을까요? 순진하게 해보면 큰 점프 + 무작위성의 조합이 품질을 망가뜨려요. 이유는 두 가지예요. 첫째, 스텝 간격이 커지면 가우시안으로 근사했던 가정이 깨져요. 한 스텝이 작을 때는 역방향이 거의 가우시안이지만, 간격이 커지면 실제 분포가 멀티모달이 돼요. 둘째, 매 스텝마다 주입되는 $\sigma_t z$ 노이즈가 누적되면서 경로가 심하게 흔들려요. 즉 큰 점프를 원한다면 무작위성부터 제거해야 한다는 아이디어가 나와요.
DDIM으로 추론을 가속해요
DDIM (Denoising Diffusion Implicit Models) 은 Song et al. (2020)이 제안한 가속 기법이에요. 핵심 아이디어는 두 가지예요.
- 무작위성을 제거해요. $\sigma_t = 0$으로 두면 샘플링이 결정론적이에요.
- 스텝을 건너뛰어요. 무작위성이 없으면 큰 점프를 해도 품질 손상이 훨씬 적아요.
DDIM의 출발점은 흥미로운 관찰이에요. ELBO의 loss 식을 다시 보면 주변 분포 $q(x_t \mid x_0)$에만 의존하고, 스텝 간 조건부 $q(x_t \mid x_{t-1})$에는 의존하지 않아요. 같은 주변 분포를 유지하는 다른 경로를 만들어도 학습된 모델을 그대로 쓸 수 있다는 뜻이에요. 재학습이 필요 없어요.
이 자유도를 이용해 결정론적인 reverse process를 설계할 수 있어요. 핵심은 “현재 $x_t$에서 깨끗한 이미지 $\hat{x}_ 0$을 먼저 예측하고, 그 $\hat{x}_ 0$을 이용해 $x_{t-1}$을 계산하는” 순서예요.
$\hat{x}_0$을 예측해요
한 번에 건너뛰는 공식을 다시 꺼내요.
\[x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1 - \bar{\alpha}_t}\, \epsilon\]이걸 $x_0$에 대해 풀면 다음과 같아요.
\[x_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t}\, \epsilon}{\sqrt{\bar{\alpha}_t}}\]모델이 예측한 $\epsilon_\theta(x_t, t)$를 $\epsilon$ 자리에 넣으면, 현재 $x_t$에서 바라보는 깨끗한 이미지 추정치 $\hat{x}_0$가 돼요.
\[\hat{x}_0(x_t, t) = \frac{x_t - \sqrt{1 - \bar{\alpha}_t}\, \epsilon_\theta(x_t, t)}{\sqrt{\bar{\alpha}_t}}\]매 스텝마다 모델이 예측한 $\hat{x}_0$은 조금씩 달라져요. 처음에는 흐릿한 평균 이미지지만, 점점 선명해지면서 최종 결과에 수렴해요.
$x_{t-1}$로 결정적으로 이동해요
$\hat{x}_ 0$을 안다면 $x_{t-1}$은 다시 한 번에 건너뛰는 공식으로 만들 수 있어요. 단, 이번에는 무작위 노이즈 대신 모델이 예측한 $\epsilon_\theta$를 그대로 재사용해요.
\[x_{t-1} = \sqrt{\bar{\alpha}_{t-1}}\, \hat{x}_0(x_t, t) + \sqrt{1 - \bar{\alpha}_{t-1}}\, \epsilon_\theta(x_t, t)\]이 식에는 가우시안 샘플링이 없어요. $x_t$가 주어지면 $x_{t-1}$이 유일하게 결정돼요. 같은 $x_T$에서 출발하면 항상 같은 이미지가 나와요. 이 성질 덕분에 latent 공간을 interpolation 하거나, 특정 이미지의 latent를 역으로 찾는 작업이 가능해져요.
스텝을 건너뛰어요
결정적 업데이트라면 굳이 $T$ 스텝을 모두 거칠 필요가 없어요. 전체 $T$ 스텝 중에서 부분 수열 $\tau_0 = 0 < \tau_1 < \cdots < \tau_S = T$를 골라, $S \ll T$개의 스텝만 돌려요. 업데이트는 다음과 같아요.
\[x_{\tau_{i-1}} = \sqrt{\bar{\alpha}_{\tau_{i-1}}}\, \hat{x}_0(x_{\tau_i}, \tau_i) + \sqrt{1 - \bar{\alpha}_{\tau_{i-1}}}\, \epsilon_\theta(x_{\tau_i}, \tau_i)\]$T = 1000$을 $S = 50$으로 줄이면 20배 가속이에요. 선택하는 $\tau$ 스케줄은 하이퍼파라미터예요. 균등 간격으로 뽑거나, 앞쪽을 촘촘하게 뽑는 식으로 조절할 수 있어요.
속도와 품질의 trade-off
CIFAR10 실험에서 가속률에 따른 FID 변화를 측정한 결과를 보면, 10배 가속까지는 품질 손실이 거의 없어요. 반면 100배를 넘어가면 품질이 크게 나빠져요.
| 가속률 | FID 변화 |
|---|---|
| 1x | baseline |
| 10x | +3% |
| 20x | +16% |
| 50x | +70% |
| 100x | +330% |
FID(Fréchet Inception Distance)는 생성 이미지의 품질을 재는 지표예요. 작을수록 좋아요. 표의 +%는 기준 대비 얼마나 나빠졌는지를 나타내요.
정리
Diffusion의 큰 그림은 이렇게 요약할 수 있어요.
Forward process는 우리가 설계한 노이즈 추가 과정이고, 가우시안의 성질 덕분에 $x_0$에서 $x_t$로 한 번에 건너뛰는 공식이 존재해요. Reverse process는 학습해야 하는 부분이지만, 로그 가능도가 직접 계산 불가능해서 ELBO라는 하한을 대신 최대화해요. ELBO를 네 단계로 전개하면 두 가우시안 사이의 KL divergence의 합으로 정리되고, 결국 노이즈 예측 MSE라는 단순한 loss로 귀결돼요.
학습한 모델로 추론할 때는 순수 노이즈에서 시작해 $T$ 스텝에 걸쳐 노이즈를 깎아내요. DDPM은 느리지만, DDIM처럼 결정적 경로로 바꾸면 품질 손실 없이 10배 이상 가속할 수 있어요. 같은 모델을 그대로 사용하기 때문에 재학습도 필요 없어요.
수식이 많아 보여도 Diffusion의 아이디어는 한 문장이에요. 노이즈를 예측하도록 학습시키고, 추론할 때는 거꾸로 걸어 내려와요. 변분 추론의 복잡한 외형 뒤에 숨은 이 단순함이 Diffusion의 매력이에요.
참고 자료
- Ho et al., Denoising Diffusion Probabilistic Models, NeurIPS 2020.
- Song et al., Denoising Diffusion Implicit Models, ICLR 2021.
- Stanford CME 296, Diffusion & Large Vision Models, Lecture 1 (Spring 2026).
- Github, afshinea/stanford-cme-296-diffusion-large-vision-models, MIT License.