RAG로 학교 공지 검색
프로젝트를 시작하며
Retrieval-Augmented Generation(RAG)를 활용해 학교 공지를 신속하게 찾는 챗봇을 구현했어요. 이 프로젝트는 Encoder + FAISS + SQLite를 이용해 로컬 GPU로 실험했으며, 문장 요약을 위해 Claude3 Sonnet을 사용했어요.
챗봇을 만든 이유는 간단해요. 강의를 듣기 위해 강의실에 앉아 있었는데, 시간이 지나도 교수님이 오지 않았어요. 이상하다고 느껴 학교 홈페이지를 확인했지만 관련 공지를 찾을 수 없었고, 학교 챗봇에 폐강 관련 공지가 있는지 물어봤지만, 모른다는 답변만 받았죠.
이후에도 챗봇을 이용해 여러 실험을 해봤지만 계속 모른다는 이야기만 반복됐어요.
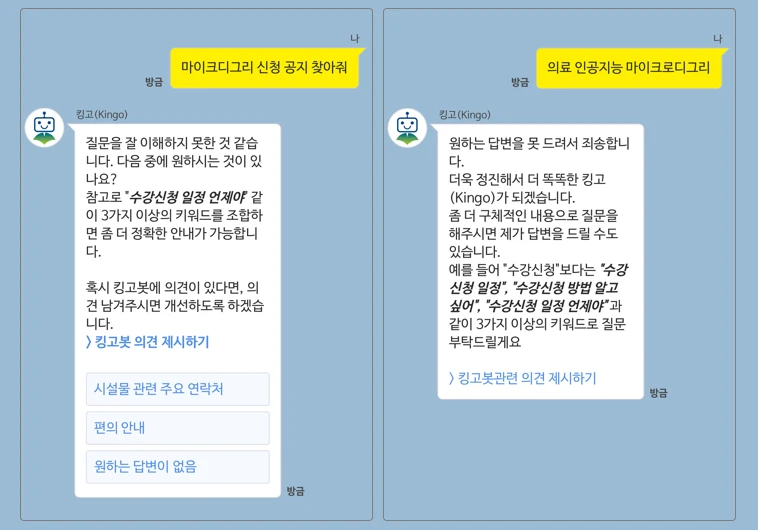
그래서 그날 밤 혼자 만든 챗봇이 바로 이 프로젝트예요.
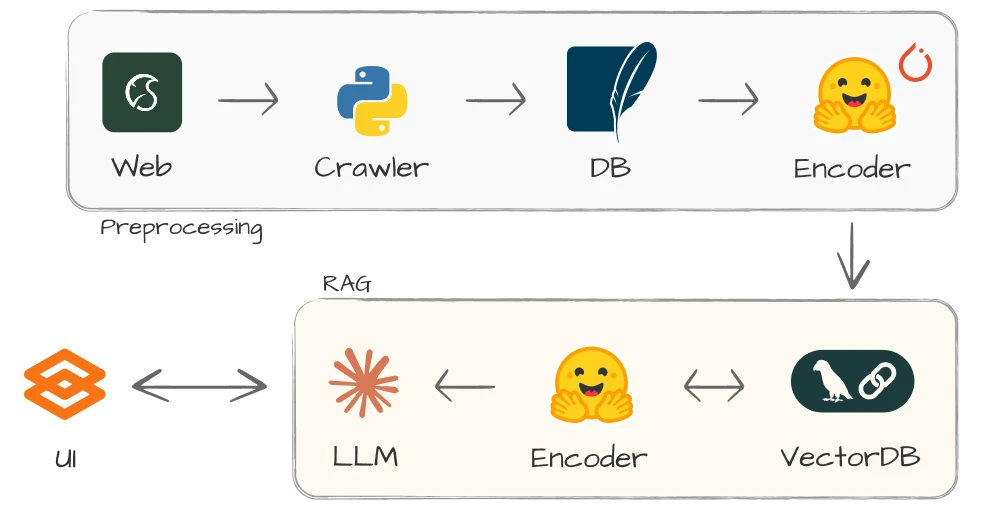
위쪽 파이프라인은 새로운 데이터를 수집하고 저장하는 과정이고, 아래쪽은 사용자가 공지를 검색하는 과정이에요.
데이터 구축
학교 홈페이지 “공지사항/학사”에서 약 300개의 글을 크롤링했어요. 그중 본문 내용이 5자 미만인 글을 제외하고, 292개의 공지를 확보했어요.
크롤링
공지 URL을 분석해보면 “?mode=view&articleNo=000“에서 articleNo를 이용해 특정 공지를 가져오는 방식이에요. 그래서 articleNo를 primary key로 삼고 id(공지번호), title(제목), content(본문)을 JSON 형식으로 저장했어요.
저장하는 과정에서 \r, \n, \s+ 등 불필요한 문자는 모두 단일 공백으로 변환했어요. 그 외에는 다른 전처리를 하지 않았어요.
SQLite
JSON을 그대로 사용해도 되지만, 조금 더 효율적인 검색을 위해 SQLite에 데이터를 저장했어요.
| id | title | content |
|---|---|---|
| 105703 | 예비군 및 병역판정… | 출석·시험·성적인정에… |
다른 데이터베이스 대신 SQLite를 사용한 이유는 단순히 가볍기 때문이에요. 데이터가 많지 않아서 SQLite로도 충분하죠.
Retriever
챗봇의 기본 원리는 관련된 공지를 찾고, 이를 바탕으로 요약하는 것이에요.
먼저 사전학습된 Encoder를 이용해 공지(텍스트)를 임베딩 벡터로 변환하고 저장해요. 이 과정에서 비슷한 문장은 가깝게, 관련 없는 문장은 멀리 위치하게 돼요. 입력 키워드가 들어오면 똑같이 임베딩 벡터로 변환한 뒤 거리가 가까운 공지를 찾게 돼요. “가까운” 공지는 “비슷한” 내용을 뜻하므로 사용자가 원하는 결과를 찾을 수 있죠.
Encoder
공지가 한국어로 작성되어 있어서 한국어를 사전학습한 KR-SBERT를 사용했어요.
1
2
3
4
from sentence_transformers import SentenceTransformer
encoder = SentenceTransformer("snunlp/KR-SBERT-V40K-klueNLI-augSTS")
encoder.encode(texts, device=device)
FAISS
임베딩 공간을 저장할 때 Facebook AI Similarity Search(FAISS)를 활용했어요. FAISS는 벡터 간 유사도를 빠르게 찾아주는 오픈소스 라이브러리예요. 임베딩된 벡터를 FAISS에 저장하고, 유사도를 계산해 K개의 유사한 벡터를 찾아와요.
1
2
3
4
hf_embeddings = HuggingFaceEmbeddings(
model_name=ENCODER_MODEL, model_kwargs={"device": device}
)
faiss_index = FAISS.from_documents(docs, hf_embeddings)
FAISS에서 검색을 완료하면 공지 내용과 id(공지번호)를 반환하도록 구현했어요. 따라서 유사한 공지의 id를 이용해 데이터베이스에서 공지 전체 내용을 조회할 수 있어요.
LLM
LLM은 가져온 정보를 요약해서 보여줘요. 물론 LLM 없이도 검색 시스템은 만들 수 있어요.

하지만 정보를 그대로 던져주는 것보다는 짧게 요약해서 보여주는 게 사용자 입장에서 더 편할 거예요. 그래서 Retriever가 물어온 정보를 LLM API를 이용해 요약해요. Version 1에서는 GPT-3.5-turbo를, Version 2는 Claude3 Sonnet을 사용했어요.
요약을 위해 사용한 프롬프트는 다음과 같아요.
1
2
3
4
5
6
7
8
9
10
11
[system]
You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Always answer in Korean based on the school notice.
{history}
[user]
Question: {user_query}
Context: {reference_documents}
Answer
결과 및 제안
데모 영상: denev6/retrieve-notice (deprecated)
Version 1
빠른 시연을 위해 Streamlit을 사용했어요. RTX 4060 위에서 임베딩 및 FAISS 검색을 처리했어요. 데모 영상 기준, 관련된 공지 3개를 찾는데 총 0.062초, LLM 요약까지 총 3.594초가 걸렸어요. 데모 영상에서 볼 수 있듯 필요한 정보를 잘 찾아왔어요.
현재 프로젝트는 최소한의 구조만 사용했지만, 아래 내용을 적용하면 성능이 더 향상될 것으로 기대돼요.
- LLM을 이용해 사용자 질문(입력)에서 키워드를 추출하고, 이를 FAISS 검색 쿼리로 사용해요.
- 검색된 K개의 공지 중 distance(거리)가 특정 threshold를 넘지 못하면, LLM 프롬프트에서 제외해요. Threshold를 직접 상수 값으로 지정해도 되고, LLM에게 판단을 맡겨도 돼요.
Version 2
Version 2는 멀티턴 대화가 가능해요. v1은 이전 대화를 기억하지 못하고, 사용자 화면에도 기록하지 않아요. v2는 대화 맥락을 저장하고, 사용자 화면에도 보여줘요. 데모 영상에서 이전 대화 정보도 잘 답변하는 모습을 보였어요.
- Gradio로 이전 대화를 화면에 보여줘요.
- Langchain으로 기록한 대화를 다음 질문에 반영해요.
LLM 모델도 변경했어요. 기존 ChatGPT-3.5에서 Claude3 Sonnet으로 변경됐어요. v1은 ‘인공지능 마이크로디그리’에 대해 질문했을 때 주어진 정보를 바탕으로 답변을 생성했어요. 하지만 v2는 주어진 정보가 부족하다고 판단해 요약만 제시하고, 자세한 정보는 모른다고 답했어요. 정보를 지어내거나 부풀리지 않았어요.
RAG로 문서를 검색할 때 v1은 문서 전체를 임베딩 했지만, v2는 chunk 단위로 나누어 저장했어요. 문서를 작은 단위로 나누면 v1에 비해 성능이 떨어졌어요. 현재는 chunk를 크게 설정해 긴 맥락을 읽을 수 있도록 했어요.
Buffer를 이용해 실시간으로 LLM 출력을 스트리밍해요. v1은 답변을 한 번에 사용자 화면으로 출력해요. 이 방식은 답변이 끝날 때까지 오랫동안 기다려야 한다는 단점이 있어요. v2는 토큰이 도착하는 대로 바로 보여주기 때문에 응답 시간이 약 1.8초 정도로 짧아졌어요.