DINO, self-distillation with no labels

이 글에서는 DINO v1의 self-distillation 프레임워크를 중심으로 핵심 기법과 수식을 살펴보고, v2와 v3에서 무엇이 바뀌었는지 정리해요.
DINO v1: Self-distillation
Emerging Properties in Self-Supervised Vision Transformers, ICCV 2021.
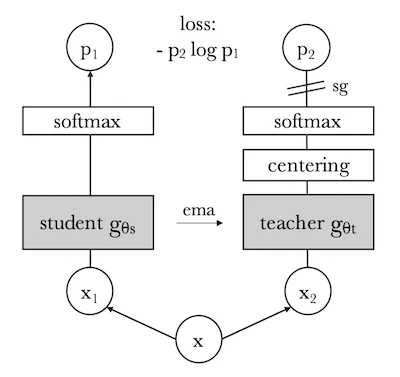
DINO는 Self-DIstillation with NO labels의 약자예요. Knowledge distillation은 학습된 teacher 모델의 출력을 student 모델이 따라하도록 학습하는 기법이에요. 재밌는 점은 DINO의 teacher도 처음부터 아무것도 모르는 상태에서 시작해요. 같은 구조의 네트워크를 2개 만들어 하나는 student $g_{\theta_s}$, 하나는 teacher $g_{\theta_t}$로 사용해요. Student는 gradient descent로 학습하고, teacher는 뒤에서 설명할 EMA로만 업데이트돼요. Teacher에는 stop-gradient가 적용되어 gradient가 student 경로로만 흘러요.
EMA Teacher
Teacher는 gradient를 받지 않고, student 파라미터의 EMA(Exponential Moving Average)로만 업데이트돼요.
\[\theta_t \leftarrow \lambda\, \theta_t + (1 - \lambda)\, \theta_s\]모멘텀 $\lambda$는 cosine schedule로 0.996에서 1.0까지 증가해요. Teacher는 student의 “평균적인 과거 버전”이에요. 이 평균 효과(Polyak-Ruppert averaging)가 개별 배치의 노이즈를 줄여 안정적인 학습 target을 제공해요. 학습 초기에는 $\lambda$가 작아서 student 변화를 빠르게 반영하고, 후반에는 1에 가까워져 거의 고정돼요.
일반적으로 distillation에서 teacher는 student 보다 높은 성능을 가진 모델이어야 해요. 그런데 EMA를 사용한다해도 student의 과거 버전을 teacher로 사용하는 게 맞나 싶을 수 있어요. 그래서 논문에서 multi-crop을 소개해요.
Multi-crop
같은 이미지에서 크기가 다른 여러 crop을 만들어요.
- Global crop 2장: 이미지의 넓은 영역을 포함하는 224×224 크기의 crop
- Local crop 여러 장: 작은 영역만 포함하는 96×96 크기의 crop
Teacher는 global crop만 보고, student는 모든 crop(global + local)을 봐요. Teacher는 더 많은 공간을 보기 때문에 상대적으로 추론이 쉬운 반면, student는 이미지의 작은 부분만 보고도 전체 이미지의 의미를 추론해야 하는 셈이에요. 이것이 local-to-global correspondence 학습의 핵심이에요.
Loss function
Student와 teacher의 출력은 각각 temperature-scaled softmax를 거쳐 확률 분포로 변환돼요. Temperature $\tau$는 분포의 뾰족한 정도를 조절하는 하이퍼파라미터예요. 값이 낮으면 가장 큰 값에 확률이 몰리고(sharp), 높으면 골고루 퍼져요(smooth).
Student의 출력 확률:
\[P_s(x)^{(i)} = \frac{\exp(g_{\theta_s}(x)^{(i)} / \tau_s)}{\sum_{k=1}^{K} \exp(g_{\theta_s}(x)^{(k)} / \tau_s)}\]Teacher의 출력 확률 (centering 적용):
\[P_t(x)^{(i)} = \frac{\exp\big((g_{\theta_t}(x)^{(i)} - c^{(i)}) / \tau_t\big)}{\sum_{k=1}^{K} \exp\big((g_{\theta_t}(x)^{(k)} - c^{(k)}) / \tau_t\big)}\]$K$는 출력 차원(65,536)이에요. Student temperature $\tau_s = 0.1$은 고정이고, teacher temperature $\tau_t$는 0.04에서 0.07로 warmup해요. Teacher의 낮은 temperature가 sharpening 효과를 만들어요. $c$는 centering vector로, 뒤에서 설명할게요.
전체 손실은 cross-entropy예요.
\[\mathcal{L} = \sum_{x \in \{x_1^g, x_2^g\}} \sum_{\substack{x' \in V \\ x' \neq x}} H(P_t(x),\; P_s(x'))\] \[H(a, b) = -\sum_i a^{(i)} \log b^{(i)}\]Teacher의 각 global crop에 대해, student의 자기 자신을 제외한 모든 crop과의 cross-entropy를 합산해요.
Centering과 Sharpening
Self-supervised 학습의 최대 위협은 representation collapse예요. 어떤 이미지를 넣어도 같은 출력이 나오면 loss는 0이지만 아무것도 배운 게 없는 상태이죠. DINO는 centering과 sharpening의 조합으로 이를 해결해요.
Centering은 teacher 출력에서 running mean을 빼는 연산이에요:
\[c \leftarrow m \cdot c + (1-m) \cdot \frac{1}{B}\sum_{i=1}^{B} g_{\theta_t}(x_i)\]모멘텀 $m=0.9$로, 최근 배치들의 teacher 출력 평균을 추적해요. 이 $c$를 빼면 하나의 차원이 모든 출력을 지배하는 mode collapse를 방지해요. 하지만 centering만 하면 모든 차원이 고르게 활성화되어 uniform distribution으로 수렴할 수 있어요.
Sharpening은 teacher의 낮은 temperature로 확률 분포를 뾰족하게 만드는 것이에요. 특정 차원에 확신을 가지도록 강제하여 uniform collapse를 방지해요.
즉, centering은 한쪽으로의 쏠림을, sharpening은 고른 분산을 각각 방지하며 서로 보완해요.
Projection Head
네트워크는 backbone $f$와 projection head $h$의 합성 $g = h \circ f$로 구성돼요. Projection head는 3-layer MLP → $L_2$ 정규화 → weight-normalized FC로 이루어져요. Downstream task에서는 projection head를 버리고 backbone 출력만 사용해요.
Emergent Properties

DINO로 학습된 ViT의 마지막 layer에서 [CLS] token의 self-attention map을 시각화하면, 라벨 없이 학습했는데도 객체 단위의 의미 분할이 나타나요. 서로 다른 attention head가 배경, 물체 전체, 특정 부위 등 각기 다른 영역에 집중해요. k-NN 분류에서도 어떠한 fine-tuning 없이 ImageNet top-1 78.3%를 달성했어요. Feature 공간이 이미 의미적으로 잘 구조화되어 있다는 증거예요.
DINOv2: 스케일링
DINOv2: Learning Robust Visual Features without Supervision, TMLR 2024.
EMA 대신 Sinkhorn-Knopp
v1의 moving average centering을 Sinkhorn-Knopp(SK) 알고리즘으로 대체했어요. SK는 teacher의 score 행렬에 대해 반복적으로 행/열 정규화를 수행하여 doubly-stochastic matrix(모든 행합 = 1, 모든 열합 = 1)를 만들어요. 열 정규화가 equipartition constraint를 강제해 하나의 prototype이 배치 전체를 지배하지 못하게 해요. v1의 centering보다 더 강건하게 mode collapse를 방지해요.
Loss function 변경
DINOv1의 loss은 [CLS] token에만 적용돼요. DINOv2는 여기에 iBOT loss를 추가하여 패치 수준의 학습을 수행해요. Student 입력의 일부 패치를 랜덤 마스킹하고, 마스킹된 위치에서 teacher의 패치 출력을 예측하도록 학습해요.
\[\mathcal{L}_{\text{iBOT}} = -\sum_{m \in \text{masked}} \sum_{k=1}^{K} p_t^{(\text{patch}, m, k)} \cdot \log\, p_s^{(\text{patch}, m, k)}\]MAE(Masked Auto-Encoder)처럼 픽셀을 복원하는 것이 아니라, teacher의 semantic output을 맞추는 것이 핵심이에요. DINOv2에서는 DINO head(CLS용)와 iBOT head(patch용)를 별도로 분리하여 사용해요.
KoLeo는 배치 내 feature들이 unit hypersphere 위에서 균일하게 퍼지도록 유도하는 정규화 기법이에요.
\[\mathcal{L}_{\text{KoLeo}} = -\frac{1}{n}\sum_{i=1}^{n} \log(d_{n,i})\]$d_{n,i}$는 $L_2$ 정규화된 [CLS] feature 간 nearest neighbor 거리예요. 이 loss는 각 feature의 nearest neighbor 거리의 로그를 최대화해서 feature들이 한곳에 뭉치는 것을 방지해요.
DINOv2의 학습 손실은 세 가지의 합이에요.
\[\mathcal{L} = \mathcal{L}_{\text{DINO}} + \mathcal{L}_{\text{iBOT}} + \lambda_{\text{KoLeo}} \cdot \mathcal{L}_{\text{KoLeo}}\]참고로 $\mathcal{L}_{\text{DINO}}$은 Image level objective이에요. DINOv1에서 했던 것처럼 teacher와 student 간의 Cross-entropy loss이에요.
아키텍처 변경
기존 FFN이 Linear → GELU → Linear 구조인 반면, DINOv2의 ViT-g는 gated linear unit인 SwiGLU FFN을 사용해요.
\[\text{SwiGLU}(x) = W_3 \cdot \big(\text{SiLU}(W_1 x) \odot W_2 x\big)\]$\text{SiLU}(x) = x \cdot \sigma(x)$이고, $\odot$은 element-wise 곱셈이에요. $W_1$ 경로는 활성화 함수를 거치고 $W_2$ 경로는 그대로 통과한 뒤 둘을 곱하는 gating mechanism이에요.
그 외에도 패치 크기를 14로 줄여 패치 해상도를 높이거나 학습 중 LayerScale을 적용하는 등 방법을 적용했어요.
LVD-142M 데이터 큐레이션
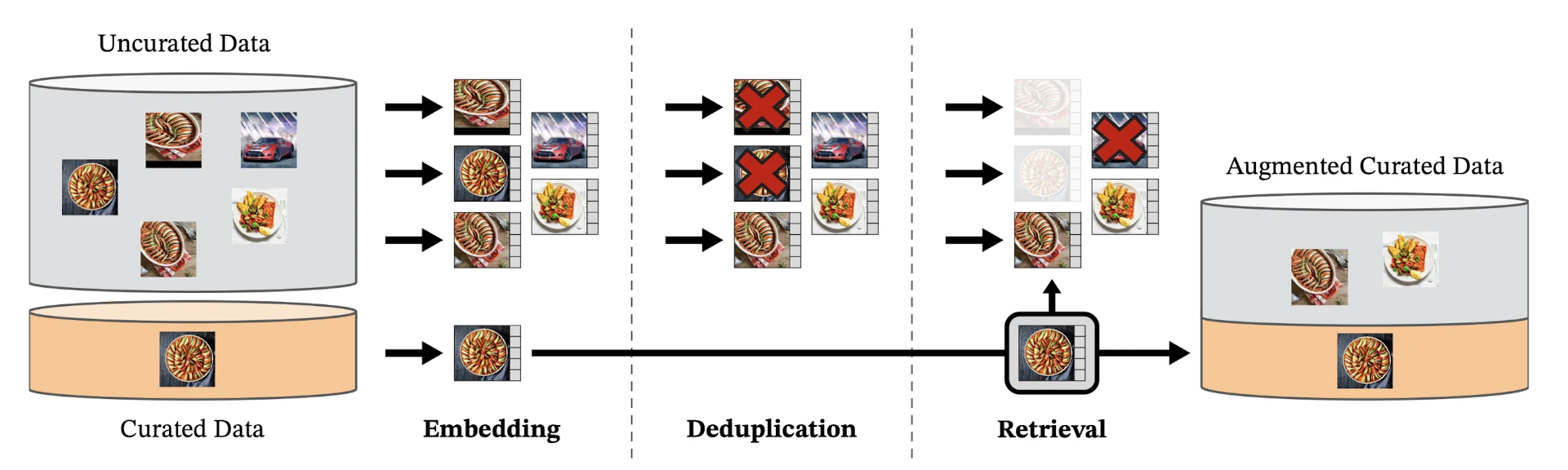
v1이 ImageNet-1k(128만 장)으로 학습한 반면, DINOv2는 자체 구축한 LVD-142M(1.42억 장)을 사용해요. 파이프라인은 세 단계예요.
- 공개 웹 크롤에서 약 12억 장의 고유 이미지 추출 + 중복 제거 + NSFW 필터링
- ImageNet-22k, Google Landmarks 등 고품질 seed 데이터셋을 self-supervised ViT-H/16으로 임베딩
- Cosine similarity 기반 k-NN 검색으로 seed와 유사한 웹 이미지를 선별
텍스트나 메타데이터 없이 이미지만으로 작동하는 것이 특징이에요.
실험 결과
- ImageNet linear probe: ViT-g/14로 86.5% top-1 (v1의 80.1%에서 향상)
- ADE-20k segmentation: linear probe 49.0 mIoU
- Domain generalization 벤치마크(ImageNet-A 등)에서 weakly-supervised 모델을 능가
DINOv3
DINOv3, 2025.
Global vs Dense의 딜레마
DINOv2를 더 크게, 더 오래 학습하면 global feature(분류 성능)는 계속 좋아지지만, dense feature(segmentation, depth estimation)는 어느 시점부터 오히려 나빠지는 현상이 관찰돼요. 학습이 진행되며 모델이 분류에 최적화되다 보면 패치 간 관계 구조가 무너져요.
Gram Anchoring
DINOv3의 핵심 기법인 Gram anchoring은 이 딜레마를 정면으로 해결해요.
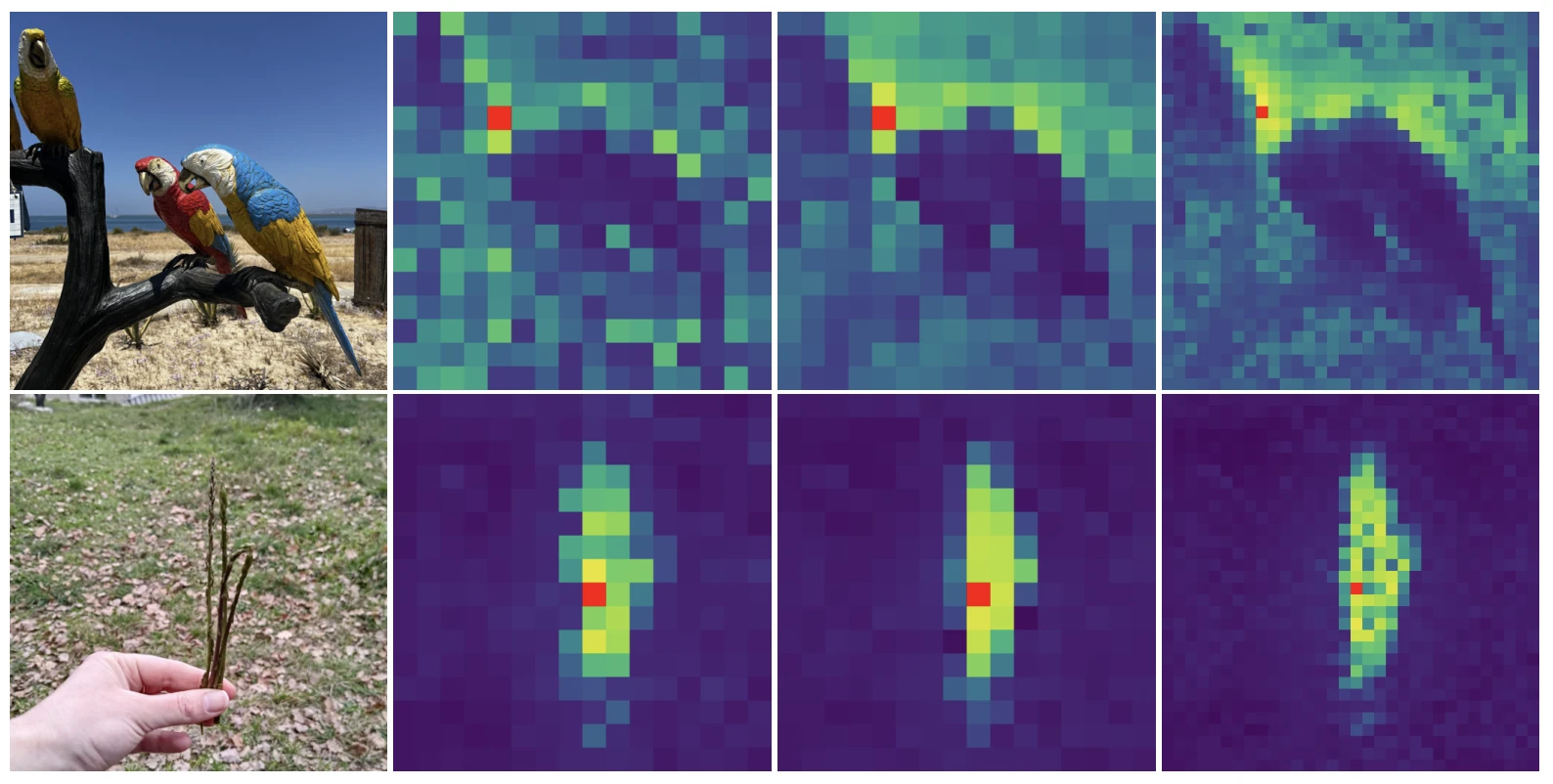 Gram matrices at different input resolutions
Gram matrices at different input resolutions
Gram matrix는 패치 임베딩 간의 pairwise 내적으로 이루어진 행렬이에요. 패치 임베딩 $X \in \mathbb{R}^{N_p \times d}$에 대해
\[G = X X^\top \in \mathbb{R}^{N_p \times N_p}\]즉 Gram matrix 전체가 “모든 패치 쌍의 관계 구조”를 담고 있어요.
Gram anchoring의 아이디어는 다음과 같아요.
- 학습 초기(dense feature가 아직 좋은 시점)의 체크포인트를 저장해요. 이것을 Gram teacher라고 불러요.
- 이후 학습에서 현재 모델의 Gram matrix가 Gram teacher의 것과 비슷하게 유지되도록 제약해요.
$|\cdot|_F$는 Frobenius norm이에요. iBOT이 개별 패치의 feature 값을 제약한다면, Gram anchoring은 모든 패치 쌍의 관계를 보존해요.

전체 Loss function
Gram anchoring phase에서의 손실은 다음과 같아요.
\[\mathcal{L}_{\text{total}} = w_D \cdot \mathcal{L}_{\text{DINO}} + \mathcal{L}_{\text{iBOT}} + w_{DK} \cdot \mathcal{L}_{\text{KoLeo}} + w_{\text{Gram}} \cdot \mathcal{L}_{\text{Gram}}\]초기 사전학습에서는 $\mathcal{L}_{\text{Gram}}$ 없이 DINOv2와 동일하게 학습하고, 이후 Gram anchoring을 추가하는 2단계 구성이에요.
6단계 학습 파이프라인
Phase 1 — 사전학습: DINO + iBOT + KoLeo 손실로 학습해요. DINOv2 대비 주요 변화로, cosine schedule을 제거하고 warmup 이후 상수 하이퍼파라미터를 사용해요. 대규모 학습에서 하이퍼파라미터 튜닝 부담을 줄여줘요.
Phase 2 — Gram anchoring: Phase 1 초기 체크포인트를 Gram teacher로 삼아 $\mathcal{L}_{\text{Gram}}$을 추가 학습해요. 짧은 기간에 dense feature가 빠르게 회복돼요.
Phase 3 — 고해상도 적응: global crop을 {512, 768}px, local crop을 {112~336}px 등 혼합 해상도로 학습해요.
Phase 4 — Multi-student distillation: 7B teacher를 고정하고 ViT-S, B, L, H+ 및 ConvNeXt 모델을 동시에 학습시켜요. Teacher inference를 학생 그룹 간 공유하여 효율적이에요.
Phase 5 — dino.txt (텍스트 정렬): Frozen backbone 위에 작은 transformer layer를 두고, LiT(Locked-image Text Tuning)-style contrastive loss로 텍스트 임베딩과 정렬해요. 이를 통해 zero-shot classification이 가능해져요.
ViT-7B와 RoPE
- ViT-7B: 6.7B 파라미터, 40 layers, embedding dim 4096, SwiGLU FFN으로 구성돼요. DINOv2의 ViT-g(1.1B)에서 약 6배 커졌어요.
- Axial RoPE with RoPE-box jittering: DINOv2의 학습된 절대 위치 임베딩을 대체해요. RoPE(Rotary Position Embeddings)는 attention 계산에서 query와 key 벡터를 위치에 따라 회전시켜 상대 위치 정보를 반영하는 기법이에요.
- RoPE-box jittering: 학습 시 crop의 좌표 범위를 랜덤하게 스케일링해요. 모델이 특정 해상도에 과적합하지 않아서, 추론 시 최대 4096×4096 해상도까지 재학습 없이 일관된 feature를 생성해요.
- Register tokens: ViT에서 배경 패치에 비정상적으로 높은 attention이 집중되는 artifact를 흡수하기 위해 4개의 register token을 추가해요.
LVD-1689M
LVD-142M과 동일한 파이프라인을 사용하되, 약 170억 장의 공개 이미지에서 시작하여 16.89억 장으로 12배 확장했어요.
실험 결과

DINOv3의 성과는 dense task에서 가장 극적이에요.
- ADE-20k segmentation: linear probe 55.9 mIoU (v2의 49.0에서 +6.9)
- COCO detection: 66.1 mAP
- Video segmentation: v2 대비 +6.7 J\&F-Mean
ImageNet 분류에서도 supervised/CLIP 모델과 동등한 수준을 유지하면서, weakly-supervised 모델마저 dense task에서 압도하는 것이 가장 의미 있는 성과예요.
정리
| v1 (2021) | v2 (2023) | v3 (2025) | |
|---|---|---|---|
| 손실 | DINO | DINO + iBOT + KoLeo | + Gram anchoring |
| Collapse 방지 | Moving avg centering | Sinkhorn-Knopp | Sinkhorn-Knopp |
| 최대 모델 | ViT-B/8 (85M) | ViT-g/14 (1.1B) | ViT-7B/16 (6.7B) |
| 학습 데이터 | ImageNet-1k | LVD-142M | LVD-1689M |
| 위치 임베딩 | Learned absolute | Learned absolute | Axial RoPE |
| Distillation | 없음 | Single-student | Multi-student |
| 텍스트 정렬 | 없음 | 없음 | dino.txt |
DINOv1을 보면 Meta의 서커스라는 표현이 알맞은 거 같아요. ‘진짜 이게 된다고?’에 한 번 놀라고, DINOv3에서 보여준 성능에 다시 한 번 놀랐어요. Pytorch 구현은 github에서 확인할 수 있어요.