발화자의 감정인식 AI 경진대회
대회: 월간 데이콘 발화자의 감정인식 AI 경진대회
제출 코드: dacon.io/codeshare
동기
자연어처리 대회를 소개받아 DACON 대회에 참가하게 되었어요. 자연어처리 과목을 수강 중이었는데 교수님께서 대회를 소개해 주셨죠. 당시 멀티모달 우울증 탐지 연구를 하고 있어서 감정 분석 모델에 대해 공부도 할 겸 참가하게 되었어요. 그래도 가장 큰 목표는 대회 우승이었답니다.
데이터 전처리
발화문 데이터 대부분이 구어체여서 정규화를 진행했어요.
Github: 전처리 코드
대부분 데이터는 20 단어 이내의 문장이고, 2~5개 단어로 구성된 문장도 포함돼 있었어요.
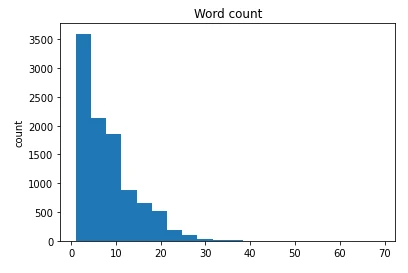
발화 문장은 특수 문자가 많이 포함된 구어체 문장인데요. didn’t 같은 축약형에서 사용하는 apostrophe(‘)도 두 종류가 섞여 있는 등 불균일한 모습이에요. Aaaaaaawwwww나 Oh-oh-oh-oh-oh처럼 같은 패턴의 문자가 반복되는 경우도 볼 수 있어요.
시도한 전처리는 아래와 같아요.
- 유사한 특수문자 통일 (i.e. “와 “)
- 소문자로 통일
-
TweetTokenizer활용 -
불용어(stopwords)제거 - 반복 표현 제거 (i.e. Oh-oh-oh-oh-oh → Oh)
- 축약 표현 복원 (i.e. didn’t→ did not)
- 의미 없는 특수 문자 제거(i.e. ‘ : Ok’→ ‘Ok’)
-
표제어추출(lemmatization)
표제어 추출이나 불용어 제거 같이 정보 손실이 많은 경우 성능이 크게 떨어졌어요.
1
2
3
4
5
6
7
8
9
10
11
12
"""
원문: I didn't break the cup!!!
축약어 복원: I did not break the cup!!!
불용어 제거: I break cup !!!
"""
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("roberta-base")
>>> tokenizer.tokenize("I didn't break the cup!!!")
['I', 'Ġdidn', "'t", 'Ġbreak', 'Ġthe', 'Ġcup', '!!!']
>>> tokenizer.tokenize("I break cup !!!")
['I', 'Ġbreak', 'Ġcup', 'Ġ', '!!!']
축약어 복원과 불용어 제거가 만나면 문장 의미가 바뀌기도 해요.
1
2
3
4
5
6
7
"""
원문: I did not break the cup!!!
표제어 추출: I do not break the cup!!!
"""
>>> tokenizer.tokenize("I do not break the cup!!!")
['I', 'Ġdo', 'Ġnot', 'Ġbreak', 'Ġthe', 'Ġcup', '!!!']
표제어 추출도 마찬가지예요. “제가 컵 안 깼어요!!!”와 “저는 컵 안 깹니다!!!”는 다른 의미라고 생각해요. 이러한 전처리를 거쳐 학습한 모델은 좋지 않은 성능을 보였어요.
그 외 전처리도 유의미한 차이는 없었지만, TweetTokenizer는 약간의 성능 향상을 보였어요. 결론적으로 원본 데이터를 최대한 유지해야 했어요.
모델 선택 및 구현
사전 학습된 파라미터 활용을 위해 Emoberta를 선택했어요.
- 문제 데이터와 같은 레이블을 가져요.
- 사전 학습된 모델이에요.
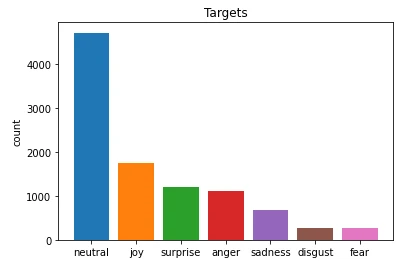
tae898/utils.py에서 레이블을 확인할 수 있었고, 동일하게 학습하도록 LabelEncoder를 생성했어요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class LabelEncoder(object):
"""EmoBERTa에 맞게 직접 생성한 인코더"""
def __init__(self):
self._targets = [
"neutral",
"joy",
"surprise",
"anger",
"sadness",
"disgust",
"fear",
]
self.target_size = len(self._targets)
def encode(self, labels):
labels = [self._targets.index(lb) for lb in labels]
return labels
def decode(self, labels):
labels = [self._targets[lb] for lb in labels]
return labels
비교를 위해 sklearn의 sklearn.preprocessing.LabelEncoder로 랜덤하게 레이블을 지정하고, 직접 만든 Encoder와 비교해 보았어요. 당연한 결과지만, EmoBERTa에 맞게 직접 만든 Label-Encoder가 확연히 더 좋은 성능을 보였답니다.
모델 변형
모델의 성능을 높이기 위해 발화문의 문맥을 해석할 수 있는 RNN 기반의 구조를 결합했어요.
- 모델 전체 Fine-tuning
- Classifier 층 (Linear~)만 학습
- Classifier 층 대신 GRU 결합 후 학습
 모델 기본 구조
모델 기본 구조
분류 모델은 RoBERTa+Classifier 형태를 가져요. 따라서 RoBERTa는 학습되지 않도록 하고, Classifier 가중치만 학습시켰어요. 학습된 모델과 해결하려는 문제가 동일하기 때문에 효과가 있을 수 있죠.
1
2
3
for name, param in emoberta.named_parameters():
if not str(name).startswith("classifier"):
param.requires_grad = False
문맥을 파악하기 위해 Classifier 대신 GRU를 사용했어요. 유사한 구조를 사용한 논문: “Sentiment Analysis With Ensemble Hybrid Deep Learning Model”에서 제시한 값과 optimizer를 참고했어요. 대신 데이터를 랜덤하게 섞지 않고 발화 순서를 유지하며 입력했답니다. 결국은 RoBERTa의 전체 구조를 유지하며 Fine-tuning하는 경우 가장 좋은 성능을 보였어요. 모델 구조의 차이보다 데이터 양의 문제라고 생각해요. EmoBERTa는 학습된 파라미터를 가지고 있지만, 학습된 값을 덜어내고 적은 데이터로 학습하면 학습량이 차이날 수밖에 없답니다.
메모리 부족 문제
큰 Batch size가 중요했지만 메모리가 부족해 Gradient Accumulation을 적용했어요. Batch size를 8, 16, 32…로 테스트했지만 메모리 에러가 발생했어요. 메모리 문제로 인해 Gradient Accumulation을 적용해 batch를 8*8, 16*8, 16*16로 키우며 테스트했어요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
model.zero_grad()
for epoch in epoch_progress:
model.train()
for batch_id, data in enumerate(train_loader, start=1):
# 학습 과정 생략...
batch_loss = criterion(output.logits, train_label.long())
batch_loss /= grad_step
batch_loss.backward()
if batch_id % grad_step == 0:
# Gradient Accumulation
optimizer.step()
model.zero_grad()
Batch size는 32가 가장 좋은 결과를 보였어요. Gradient Accumulation을 적용한 경우 16*16과 32*8에서 더 좋은 성능을 보였죠.(Colab Pro에서 실행했고, Batch size로 32가 한계였어요.)
결과
모델 Accuracy는 0.76877, F1-macro는 0.66016가 나왔어요. test set에 대해서는 F1-macro가 0.56172로 대회 2위를 수상했답니다.

느낀점
전공으로 자연어 처리를 수강하며 NLP를 처음 접했고, transformer 모델을 처음 다루며 하루 종일 삽질만 하기도 했어요. 생각 없이 만져보다 결국 기억이 안 나서 처음부터 시작하기도 했죠. 다행히 정신 차리고 변경한 내용을 기록하며 어떤 요소가 얼마나 영향을 주었는지 비교했어요. Base 모델부터 차근차근 기록해야 한다는 사실을 뼈저리게 느꼈답니다. 너무 Private score(DACON 대회 중 공개되는 점수)에 집착하다 보니 큰 그림을 그리지 못했다는 아쉬움도 있었어요. 그래도 문제들을 해결하기 위해 Label Smootiong이나 Gradient Accumulation 등 새로운 개념도 알게 되었고, 배운 게 많은 프로젝트가 되었답니다.
다양한 모델 학습 기록: deep-learning-codes/roberta