Co-learning을 활용한 멀티모달 학습
ViLBERT, SimCLR, CLIP, ImageBind 4가지 모델을 예시로, 이미지와 다른 모달리티 간 co-learning을 살펴봐요.
Co-learning
Multi-modal learning에서 co-learning은 한 모달리티를 학습하기 위해 다른 모달리티를 활용하는 방법이에요. 예를 들어, “강아지”라는 텍스트의 특성을 파악하기 위해 강아지 이미지를 함께 학습하는 식이죠.
이번 글에서는 대표적인 두 모델 ViLBERT와 CLIP을 살펴볼게요.
ViLBERT
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks

기본적으로 BERT 구조를 사용해 특징을 추출해요. 각 모달리티의 데이터를 embed한 후 co-attention을 통해 모달리티 간 정보를 상호 학습해요.
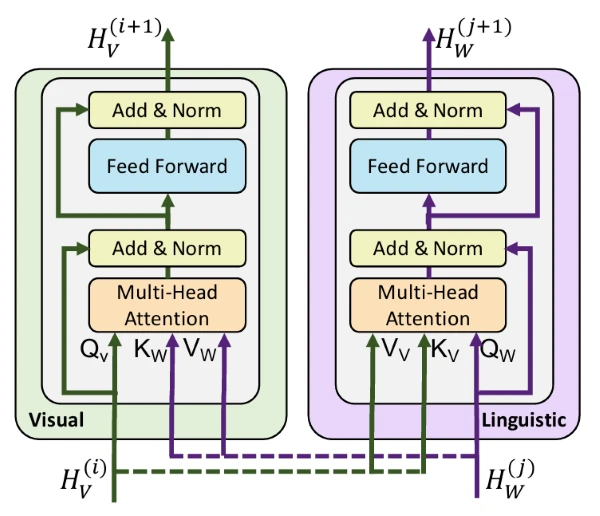
co-attention에서는 자신의 모달리티를 Query로, 다른 모달리티를 Key-Value로 사용해요. 예를 들어 Visual block은 강아지 이미지를 Query로 사용하고, Key와 Value로 “A pile of sleeping puppies”라는 문장을 사용해요. 이렇게 이미지 query와 문장 key의 관계를 파악해 서로 어떤 정보가 연결되어 있는지 학습해요. 마지막으로 value로 들어온 문장 “A pile of sleeping puppies”의 각 토큰이 이미지의 어떤 부분과 얼마나 관련 있는지 매핑해요.

언어 모델 학습
BERT와 마찬가지로 단어를 토큰 단위로 임베딩하며, <SEP>, <MASK>, <CLS>와 같은 특수 토큰을 사용해요. Attention block 전에 positional encoding을 통해 위치 정보를 주입해요. 단순히 단어 토큰 간 관계를 파악하는 것이 목적이지만, 이 경우 명확한 ground-truth 레이블을 매기기 힘들어요. 그래서 BERT에서 했던 것과 마찬가지로 2개의 과제를 만들어 학습에 사용해요.
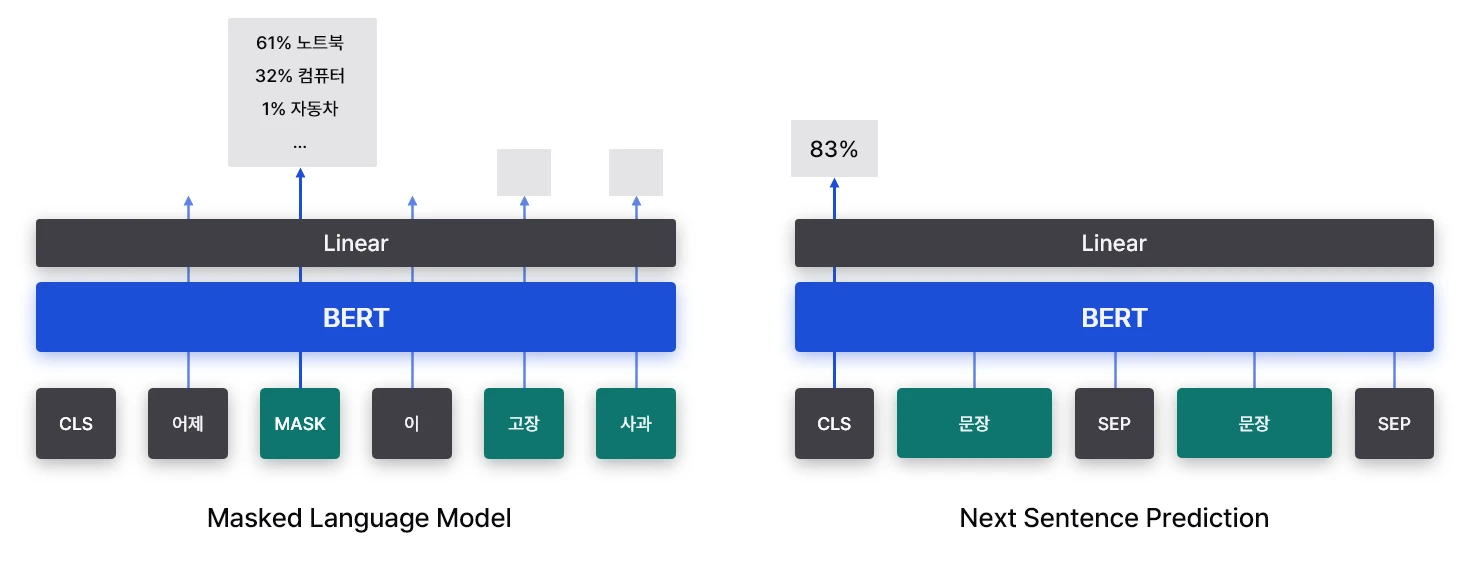
Masked Language Modeling에서는 랜덤하게 15% 정도의 토큰을 마스킹해요. 이 중 80%는 <MASK>로 대체되고, 10%는 랜덤한 단어로 대체되며, 10%는 그대로 유지돼요. 마지막에 유지되는 10%의 토큰은 원본과 동일하지만 예측 대상에 포함돼요. 모델은 문장 중간에 비어있는 단어를 예측하거나 올바른지 확인하면서 문맥 이해 능력을 학습해요. 구체적으로, 마지막 hidden layer의 출력을 정답 레이블과 비교해 가중치를 학습해요.
Next Sentence Prediction 문제는 두 문장을 이어 붙이고 자연스러운 문장이 이어졌는지 판단해요. 예를 들어, “<CLS> 노트북이 고장났다 <SEP> 급하게 수리점에 갔다 <SEP>“를 입력으로 준 뒤, <CLS> 토큰을 Linear layer로 보내 두 문장이 관련된 정도를 계산해요. 이를 정답 레이블과 비교해 가중치를 학습해요.
시각 정보 학습

먼저 Faster R-CNN을 이용해 이미지 내의 object bounding box를 추출하고 이 정보를 이미지 feature vector와 spatial(positional) encoding 정보로 사용해요. Spatial encoding은 bounding box의 top-left 좌표(2개), bottom-right 좌표(2개), 객체 영역이 전체에서 차지하는 비율(1개)로 구성된 5D 벡터를 가지게 돼요. Faster R-CNN의 내부에서 추출된 feature vector와 spatial encoding을 합쳐 최종적으로 image embedding을 출력해요. 참고로 이미지의 시작은 <IMG> 토큰을 사용해요.
Multimodal learning도 마찬가지로 masked learning과 alignment prediction 문제를 풀며 학습해요.
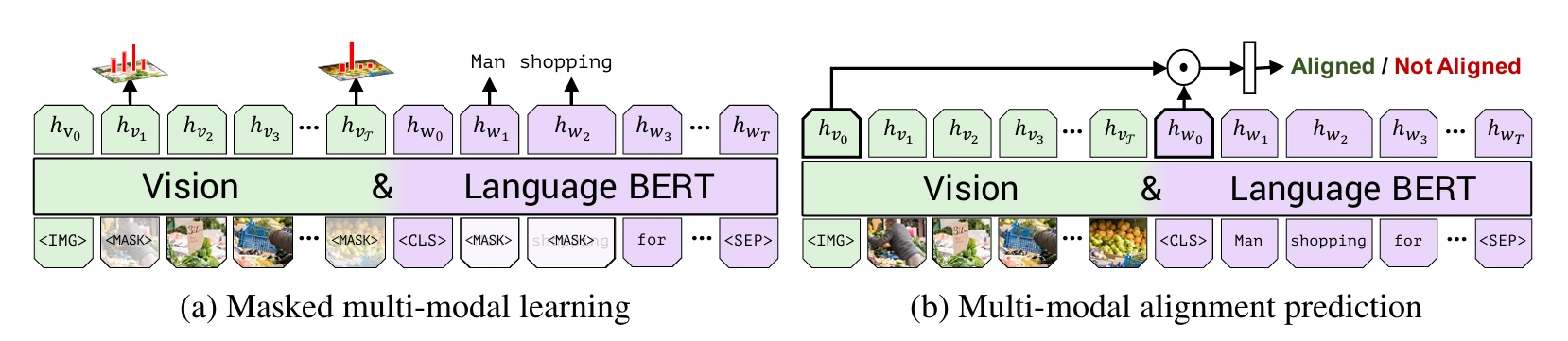
Masked Learning에서는 마스킹할 이미지 토큰 15%를 정하고, 이 중 90%은 0(zero)으로 처리하고 10%는 그대로 둬요. 이렇게 예측된 마스킹 이미지 토큰의 확률 분포는 Faster R-CNN의 분포를 정답으로 간주하고 KL divergence로 학습해요. 예를 들어, ViLBERT가 1번 이미지 패치를 { 80% 강아지, 12% 토끼, … }로 예측했고, Faster R-CNN이 { 93% 강아지, 3% 늑대 … }로 예측했다면 Faster R-CNN의 확률 분포에 가까워지도록 ViLBERT의 가중치를 조정해요.
Alignment Prediction은 이미지의 특징을 가진 <IMG> 토큰과 문장의 특징을 가진 <CLS> 토큰을 Linear layer에 넣고 이미지와 문장이 관련 있는지 판단해요. 언어 모델을 학습할 때 두 문장이 관련 있는지 예측했던 것처럼 이번에는 image-caption의 관계를 분석하는 과제를 통해 두 모달리티 간 관계를 학습해요.
모델 응용

ViLBERT는 두 모달리티의 관계를 학습하고, 이미지와 텍스트를 모두 이해하는 가중치를 학습하는 것이 목표예요. 이렇게 학습된 베이스 모델은 여러 downstream task를 풀기 위해 fine-tune할 수 있어요.
Contrastive Learning
A Simple Framework for Contrastive Learning of Visual Representations

Contrastive Learning은 positive pair는 가깝게, negative pair는 멀리 위치하도록 데이터를 정렬하는 기법이에요. 다시 말해, 연관 있는 데이터는 유사도를 높게, 반대는 유사도를 낮게 계산하도록 데이터를 학습해요.
Loss function
먼저, 데이터에 대해 positive pair $(\tilde{x_i}, \tilde{x_j})$를 정의해요. 이미지 $x_i$에 대해 Random Cropping + Resize, Random Color Distortion, Random Gaussian Blur 등 augmentation 기법을 적용해 $\tilde{x_i}$를 생성해요. 이미지 $\tilde{x_i}$는 Representation(예: ResNet) + Projection을 통해 $z_i$로 변환돼요.
Loss function은 positive pair에 대한 Consine Similarity + Cross-Entropy Loss로 생각할 수 있어요.
\[\ell_{i,j} = -\log \frac{\exp(\text{sim}(\mathbf{z}i, \mathbf{z}j)/\tau)}{\sum_{k=1}^{2N} \mathbf{1}_{[k \neq i]} \exp(\text{sim}(\mathbf{z}_i, \mathbf{z}_k)/\tau)}\] \[\mathbf{1}_{[k\neq i]} \in \{ 0, 1 \}, 1 \ \text{iff} \ k \neq i\] \[sim(u,v)=u^Tv / ||u|| ||v||\]참고로 $\tau$는 Temperature parameters예요.
N개의 pair에 대해 랜덤한 minibatch를 생성하면 총 2N개의 data point가 생성되고, 1개의 positive pair를 제외한 나머지 2(N-1)개의 point는 negative example로 취급할 수 있어요. 따라서 분자의 positive pair 간 유사도는 크게, 분모의 negative pair 유사도의 합은 작게 만들어야 해요. 이 Loss를 NT-Xent Loss라고 불러요.
학습 효과
Positive pair를 만들 때 어떤 augmentation을 적용하는가에 따라 학습 성능이 달라져요. Random Cropping + Color Distortion이 학습에 유리하며, 비대칭(asymmetric) 변환은 학습에 부정적인 영향을 줘요. 또한 supervised learning에서 불리한 augmentation 방법이 contrastive learning에는 유리할 수 있어요. 하나의 예시가 강한 color distortion을 주는 방식이에요.
$L_2$ normalization이 없으면 contrastive task accuracy는 높아지지만, 결과 representation은 악화돼요. 이는 벡터의 크기가 커지면 유사도도 커지는 꼼수를 활용하기 때문이에요. 따라서 representation을 잘 학습하기 위해서는 $L_2$ normalization을 이용해 크기를 제한하는 것이 효과적이에요.
Contrastive Learning에서는 큰 batch 크기가 중요해요. Batch의 크기가 크다는 것은 그만큼 많은 negative pair가 학습되기 때문이에요. 하지만 training epoch이 100을 넘어가면 batch 크기에 의한 효과가 줄어들어요.
CLIP
CLIP: Learning Transferable Visual Models From Natural Language Supervision
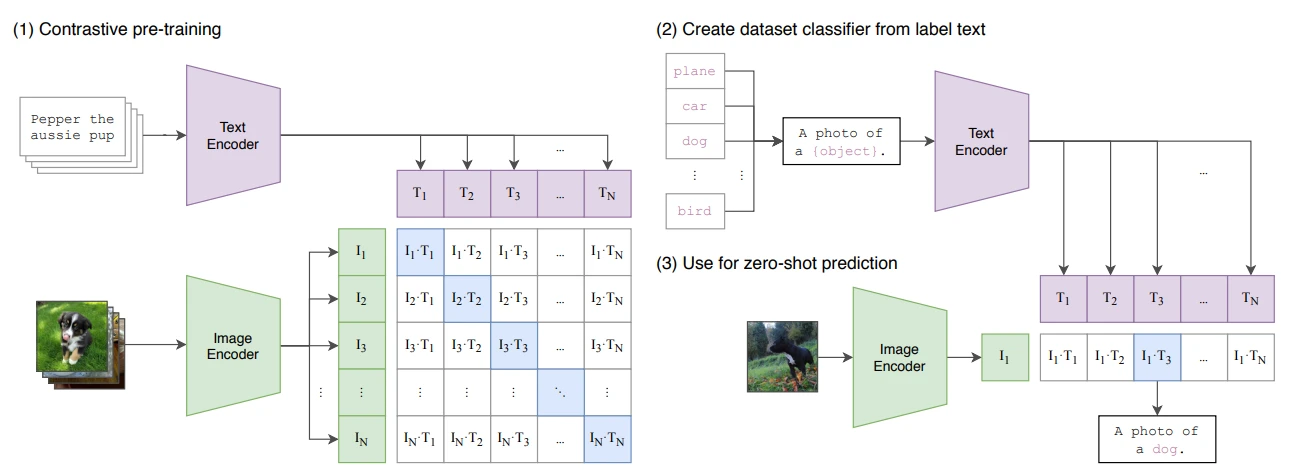
Contrastive Learning을 사용하는 가장 대표적인 예시가 CLIP이에요. 하나의 batch는 $N$개의 (image, text) pair로 구성돼요. 위에서 살펴본 Contrastive Loss를 이용해 이미지와 텍스트 임베딩 유사도가 높아지는 방향으로 이미지 인코더와 텍스트 인코더를 학습해요. 동시에 $N^2 - N$개의 negative pair와의 유사도는 작아지도록 학습해요.
이렇게 학습된 multi-modal representation은 OCR, geo-localization, action recognition 등 많은 과제를 수행하는데 사용되고 있어요.
ImageBind
Imagebind: One embedding space to bind them all
Imagebind는 contrastive loss를 이용해 이미지와 텍스트, 오디오, depth(깊이), thermal(온도) 등을 align해요.

이미지-텍스트, 이미지-오디오와 같이 이미지를 중심으로 다른 모달리티와의 관계를 학습해요. 이때는 InfoNCE loss라는 조금 다른 형태를 사용해요.
\[L_{\mathcal{I}, \mathcal{M}} = -\log \frac{\exp(\mathbf{q}_i^\top \mathbf{k}_i / \tau)}{\exp(\mathbf{q}_i^\top \mathbf{k}_i / \tau) + \sum_{j \neq i} \exp(\mathbf{q}_i^\top \mathbf{k}_j / \tau)}\] \[\mathbf{q}_i = f(\mathbf{I}_i) \ , \ \mathbf{k}_i = g(\mathbf{M}_i)\]이미지와 다른 모달리티의 positive pair $(\mathcal{I}, \mathcal{M})$를 각각 deep network로 normalized embedding한 벡터를 $\mathbf{q}$와 $\mathbf{k}$으로 표현해요. InfoNCE loss 또한 positive pair를 가깝게, negative pair를 멀게 한다는 맥락은 동일해요. 실제 구현에서는 symmetric loss $L_{\mathcal{I}, \mathcal{M}}+L_{\mathcal{M}, \mathcal{I}}$을 사용했어요.
모델을 학습한 결과, emergent compositionality가 발생하며 학습하지 않은 모달리티 간 align이 관찰되었어요. 이러한 풍부한 능력을 바탕으로 여러 downstream task도 잘 해결했어요.